一、zookeeper 简介
zookeeper 是一个开源的分布式协调服务,目前由 apache 进行维护。zookeeper 可以用于实现分布式系统中常见的发布/订阅、负载均衡、命令服务、分布式协调/通知、集群管理、master 选举、分布式锁和分布式队列等功能。 它具有以下特性:
顺序一致性: 来自客户端的更新操作将会按照顺序被应用;
原子性: 即要么全部更新成功,要么要不更新失败,没有部分的结果;
统一的系统镜像: 即不管客户端连接的是哪台服务器,都能看到同样的服务视图(也就是无状态的)
可靠性: 一旦写入操作被执行,那么这个状态将会被持久化,直到其它客户端的修改生效。
实时性: 一旦一个事务被成功应用,zookeeper 可以保证客户端立即读取到这个事务变更后的最新状态的数据。
1.zookeeper 设计目标
- zookeeper 致力于为那些高吞吐的大型分布式系统提供一个高性能、高可用、且具有严格顺序访问控制能力的分布式协调服务。
1)简单的数据模型:
zookeeper 通过树形结构来存储数据,它由一系列被称为 znode 的数据节点组成,类似于常见的文件系统;
不过和常见的文件系统不同,zookeeper 将数据全量存储在内存中,以此来实现高吞吐,减少访问延迟。
2)可配置 cluster:
为了保证高可用,最好是以集群形态部署 zookeeper,这样只要集群中大部分机器是可用的,那么 zookeeper 本身仍然可用。
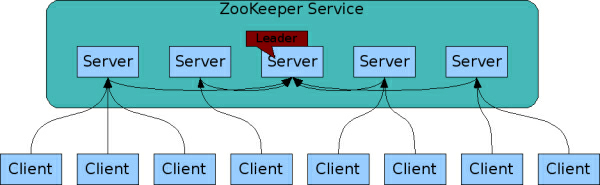
上图中每一个 server 代表一个安装 zookeeper 服务的服务器,组成 zookeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器间都保持着通信。并通过 zab 协议来保持数据的一致性。
3)顺序访问:
对于来自客户端的每个更新请求,zookeeper 都会分配一个全局唯一的递增 id,这个 id 决定了所有事务操作的先后顺序。
4)高性能高可用
zookeeper 将数据全量存储在内存中以保持高性能,并通过服务集群来实现高可用;由于 zookeeper 的所有更新和删除都是基于事务的,所以其在读多写少的应用场景中有着很高的性能表现。
2.核心概念
cluster 角色:
| 角色 | 作用 |
|---|---|
| leader | 提供读写服务,并维护集群状态(经过选举产生) |
| follower | 提供读写服务,并定期向 leader 汇报自己的节点状态(同时也参加 过半写成功 的策略和 leader 的选举) |
| observer | 提供读写服务,并定期向 leader 汇报自己的节点状态(因为不参加策略和选举,所以可以在不影响写性能的情况下提升集群的读性能) |
1)session 会话
当 client 通过 tcp 长连接 连接到 zookeeper 服务器时,session 便开始建立连接,并通过 ticktime(心跳检测)机制来保持有效的会话状态。通过这个连接,client 可以发送请求并接收响应,同时也可以接收到 watch 事件的通知。
另外,当由于网络故障或者 client 主动断开等原因,导致连接断开,此时只要在会话超时时间之内重新建立连接,则之间创建的会话依然有效。(这个取决于 ticktime 配置)
2)数据节点
zookeeper 数据模型是由一系列基本数据单元 znode(数据节点)组成的节点树,其中根节点为 /(每个节点上都会保存自己的数据和节点信息);zookeeper 中的节点可以分为两大类:
持久节点: 节点一旦创建,除非被主动删除,否则一直存在。
临时节点: 一旦创建该节点的客户端会话(session)失效,则所有该客户端创建的临时节点都会被删除。
3)watcher
zookeeper 中一个常用的功能是 watcher(事件监听器),它允许用户在指定节点上针对感兴趣的事件注册监听,当事件发生时,监听器会被触发,并将事件推送到客户端。该机制是 zookeeper 实现分布式协调服务的重要特性。
4)acl
| 命令 | 作用 |
|---|---|
create | 可以进行创建操作 |
read | 可以进行查看操作 |
write | 可以对创建的内容进行写入操作 |
delete | 可以进行删除操作 |
admin | 可以进行配置权限操作 |
命令作用create可以进行创建操作read可以进行查看操作write可以对创建的内容进行写入操作delete可以进行删除操作admin可以进行配置权限操作
3.zab 协议介绍
zab(zookeeper atomic broadcast 原子广播)协议是为分布式协调服务 zookeeper 专门设计的一种 支持崩溃恢复的原子广播协议;
在 zookeeper 中,主要依赖 zab 协议来实现分布式数据一致性;
基于 zab 协议,zookeeper 实现了一种主备模式的系统架构来保持集群中各个副本间的数据一致性。
二、zookeeper cluster 安装
准备工作:
| 主机名 | 操作系统 | ip 地址 |
|---|---|---|
| zookeeper | centos 7.4 | 192.168.1.1 |
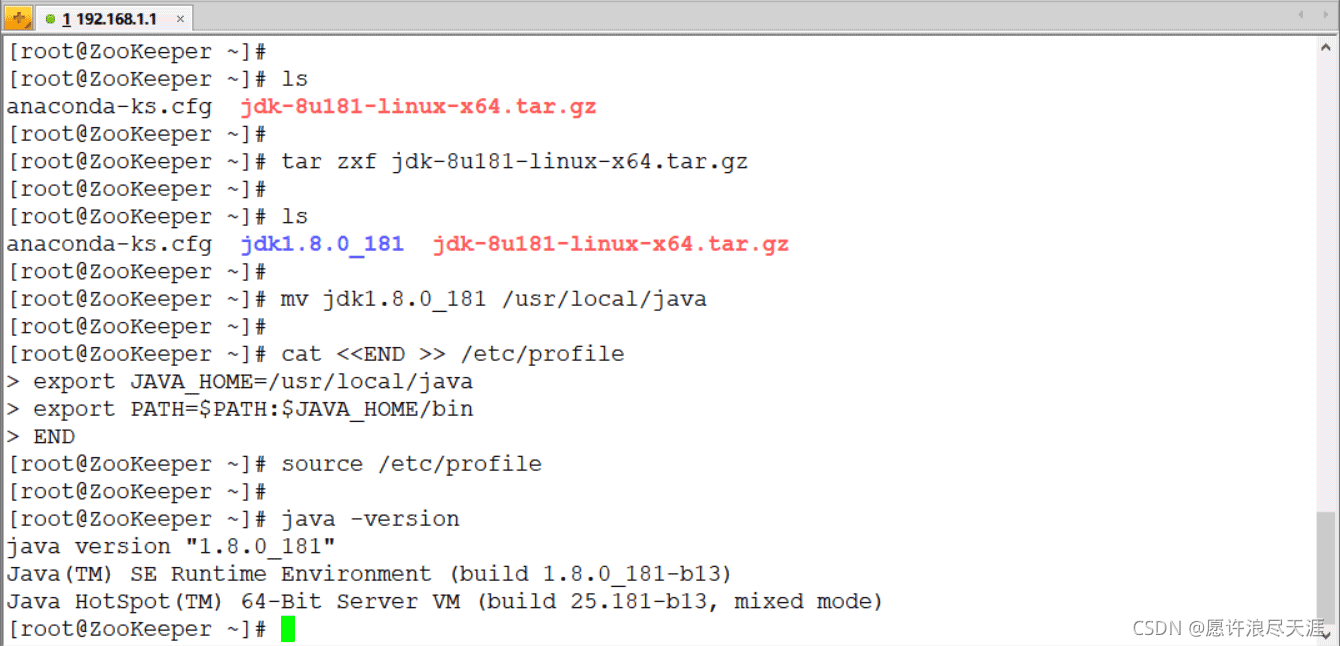
安装 jdk:下载地址(需要创建 oracle 账号)
[root@zookeeper ~]# ls anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz [root@zookeeper ~]# tar zxf jdk-8u181-linux-x64.tar.gz [root@zookeeper ~]# ls anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz [root@zookeeper ~]# mv jdk1.8.0_181 /usr/local/java [root@zookeeper ~]# cat <<end >> /etc/profile export java_home=/usr/local/java export path=$path:$java_home/bin end [root@zookeeper ~]# source /etc/profile [root@zookeeper ~]# java -version
1.安装 zookeeper
[root@zookeeper ~]# wget http://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz [root@zookeeper ~]# ls anaconda-ks.cfg apache-zookeeper-3.6.3-bin.tar.gz jdk-8u181-linux-x64.tar.gz [root@zookeeper ~]# tar zxf apache-zookeeper-3.6.3-bin.tar.gz [root@zookeeper ~]# mv apache-zookeeper-3.6.3-bin /usr/local/zookeeper [root@zookeeper ~]# mkdir /usr/local/zookeeper/data [root@zookeeper ~]# cat <<end >> /usr/local/zookeeper/conf/zoo.cfg ticktime=2000 initlimit=10 synclimit=5 datadir=/usr/local/zookeeper/data clientport=2181 end
注解:
ticktime:client 和服务器间的通信会话限制(相当于健康检查,ticktime 的时间为 ms (1s = 1000ms))
initlimit:leader 和 follower 间初始通信限制。
synclimit:leader 和 follower 间同步通信限制(当响应时间超于 synclimit * ticktime 时,leader 便会将 follower 进行移除)
datadir:此目录用于存放保存在内存数据库中的快照信息(当未配置 datalogdir 参数时,日志信息也会存放到此目录)
clientport:zookeeper 监听的端口,用于客户端连接使用。
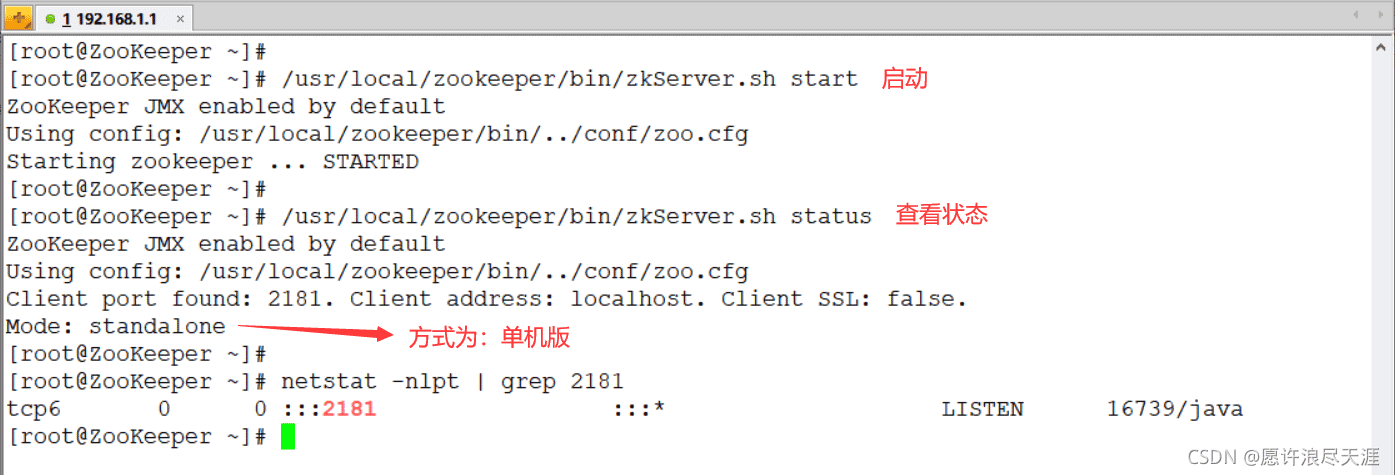
启动 zookeeper
[root@zookeeper ~]# /usr/local/zookeeper/bin/zkserver.sh start # 启动 [root@zookeeper ~]# /usr/local/zookeeper/bin/zkserver.sh status # 查看状态
连接到 zookeeper
[root@zookeeper ~]# /usr/local/zookeeper/bin/zkcli.sh -server 127.0.0.1:2181 welcome to zookeeper! jline support is enabled watcher:: watchedevent state:syncconnected type:none path:null [zk: 127.0.0.1:2181(connected) 0]
当连接成功后,系统会输出 zookeeper 的相关配置信息和相关环境,并在屏幕上输出 welcome to zookeeper! 等信息。
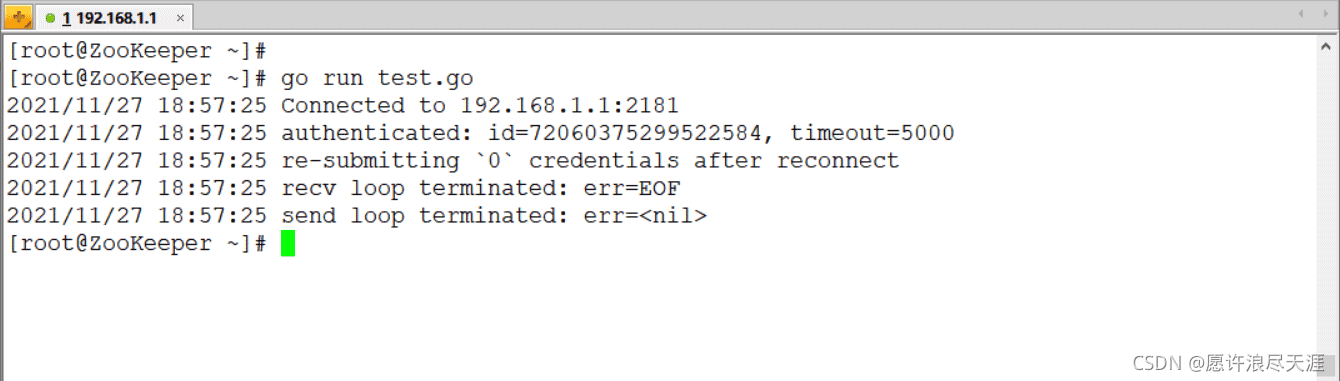
2.使用 golang 连接 zookeeper 的 api 接口
[root@zookeeper ~]# git clone https://github.com/samuel/go-zookeeper.git [root@zookeeper ~]# mv go-zookeeper /usr/local/go/src/
package main
import (
"fmt"
"time"
"go-zookeeper/zk"
)
func main() {
hosts := []string{"192.168.1.1:2181"}
conn, _, err := zk.connect(hosts,time.second * 5)
defer conn.close()
if err != nil {
fmt.println(err)
return
}
}
通过 golang 实现对 zookeeper 的增删改查:
package main
import (
"fmt"
"time"
"go-zookeeper/zk"
)
var (
path = "/zzz"
)
//增
func add(conn *zk.conn) {
var data = []byte("hello zookeeper")
// flags 的四种取值方式:
// 0 (永久.除非手动删除)
// zk.flagephemeral = 1 (短暂. session 断开则该节点也被删除)
// zk.flagsequence = 2 (会自动在节点后面添加序号)
// 3 (ephemeral 和 sequence. 即短暂且自动添加序号)
var flags int32 = 0
// 获取访问控制权限
acls := zk.worldacl(zk.permall)
create, err := conn.create(path,data,flags,acls)
if err != nil {
fmt.printf("创建失败: %v\n",err)
return
}
fmt.printf("创建: %v 成功\n",create)
}
// 查
func get(conn *zk.conn) {
data, _, err := conn.get(path)
if err != nil {
fmt.printf("查询 %s 失败,err: %v\n",path,err)
return
}
fmt.printf("%s 的值为 %s\n",path,string(data))
}
// 删除与增加不同在于其函数中的 version 参数. 其中 version 使用 cas 支持 (可以通过此种方式保证原子性)
// 改
func modify(conn *zk.conn) {
new_data := []byte("this is zookeeper")
_, sate, _ := conn.get(path)
_, err := conn.set(path,new_data,sate.version)
if err != nil {
fmt.printf("数据修改失败: %v\n",err)
return
}
fmt.println("数据修改成功")
}
// 删
func del(conn *zk.conn) {
_, sate, _ := conn.get(path)
err := conn.delete(path,sate.version)
if err != nil {
fmt.printf("数据删除失败: %v\n",err)
return
}
fmt.println("数据删除成功")
}
func main() {
hosts := []string{"192.168.1.1:2181"}
conn, _, err := zk.connect(hosts,time.second * 5)
defer conn.close()
if err != nil {
fmt.println(err)
return
}
/* 增删改查 */
add(conn)
get(conn)
modify(conn)
get(conn)
del(conn)
}
3.配置 zookeeper cluster
在原来的基础上,在增加两台服务器:
| 主机名 | 操作系统 | ip 地址 |
|---|---|---|
| zookeeper-2 | centos 7.4 | 192.168.1.2 |
| zookeeper-3 | centos 7.4 | 192.168.1.3 |
1)将 java 和 zookeeper 传给新的服务器:
[root@zookeeper ~]# scp -r /usr/local/java root@192.168.1.2:/usr/local/ [root@zookeeper ~]# scp -r /usr/local/zookeeper root@192.168.1.2:/usr/local/
2)在新的服务器上启动 zookeeper:
[root@zookeeper ~]# cat <<end >> /etc/profile export java_home=/usr/local/java export path=$path:$java_home/bin end [root@zookeeper ~]# source /etc/profile [root@zookeeper ~]# /usr/local/zookeeper/bin/zkserver.sh start
3)配置 cluster 集群(三台服务器上操作一样)
[root@zookeeper ~]# cat <<end >> /usr/local/zookeeper/conf/zoo.cfg server.1=192.168.1.1:2888:3888 server.2=192.168.1.2:2889:3889 server.3=192.168.1.3:2890:3890 end
4)创建 myid 文件
[root@zookeeper ~]# echo "1" > /usr/local/zookeeper/data/myid [root@zookeeper-2 ~]# echo "2" > /usr/local/zookeeper/data/myid [root@zookeeper-2 ~]# echo "3" > /usr/local/zookeeper/data/myid
需要确保每台服务器的 myid 文件中数字不同,并且和自己所在机器的 zoo.cfg 中 server.id=host:port:port 的 id 值一样。
另外,id 的范围是 1 ~ 255。
5)重启 zookeeper 服务
[root@zookeeper ~]# /usr/local/zookeeper/bin/zkserver.sh restart # 三台服务器都要重启
查看 zookeeper 状态:
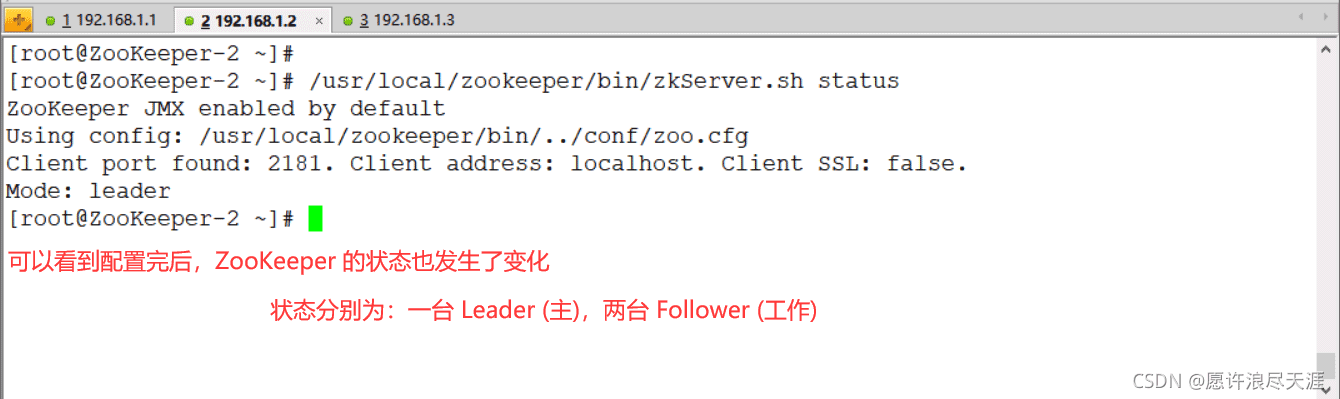
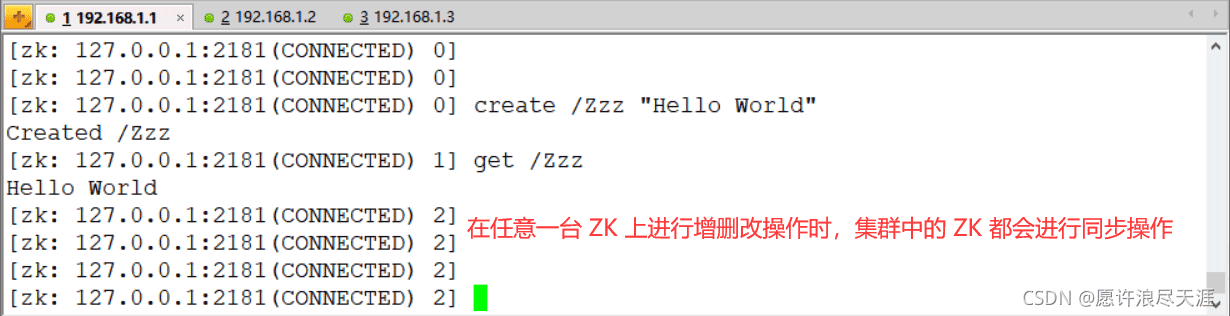
验证:
以上就是zookeeper分布式协调服务设计核心概念及安装配置的详细内容,更多关于zookeeper分布式协调服务核心安装配置的资料请关注代码网其它相关文章!
发表评论