前言
数据库死锁(deadlock)是指在并发环境中,两个或多个事务因相互等待彼此持有的资源而无法继续执行,形成一种“僵局”。死锁会导致数据库中的事务无法正常完成,严重影响系统性能和用户体验。在高并发、复杂事务操作的应用场景中,死锁问题尤为常见。了解如何排查和解决数据库死锁问题,对于确保数据库性能和系统稳定性至关重要。
本文将深入讲解数据库死锁的原理,分析常见的死锁场景,并通过实际案例,介绍如何排查和解决死锁问题,确保系统能够高效、稳定地运行。
一、数据库死锁的概念
什么是数据库死锁?
数据库死锁是一种特殊的并发问题,指两个或多个事务在并发操作时,因相互等待对方释放资源(如锁)而无法继续进行,导致这组事务永远处于等待状态。死锁可能会导致数据库中的事务超时,无法完成。
死锁的形成条件
死锁的形成通常需要满足以下四个必要条件:
第一条件是互斥:资源不能被多个线程共享,一次只能由一个线程使用。如果一个线程已经占用了一个资源,其他请求该资源的线程必须等待,直到资源被释放。
第二个条件是持有并等待:一个线程已经持有一个资源,并且在等待获取其他线程持有的资源。
第三个条件是不可抢占:资源不能被强制从线程中夺走,必须等线程自己释放。
第四个条件是循环等待:存在一种线程等待链,线程 a 等待线程 b 持有的资源,线程 b 等待线程 c 持有的资源,直到线程 n 又等待线程 a 持有的资源。
二、mysql 死锁的成因
1. 事务访问顺序不一致(最常见)
当多个事务以不同的顺序请求资源时,容易形成循环等待链,导致死锁。
案例:转账业务中的死锁
-- 事务a start transaction; update accounts set balance = balance - 100 where id = 1; -- 锁定账户1 -- 等待一段时间后 update accounts set balance = balance + 100 where id = 2; -- 尝试锁定账户2 -- 事务b start transaction; update accounts set balance = balance - 200 where id = 2; -- 锁定账户2 -- 等待一段时间后 update accounts set balance = balance + 200 where id = 1; -- 尝试锁定账户1
死锁原因:事务a和事务b分别持有对方需要的锁,形成循环等待。

2. 长事务持锁不释放
事务执行时间过长,未及时提交或回滚,导致锁资源长时间被占用。
案例:长事务导致行锁不释放产生阻塞
-- 事务a -- 开始事务 start transaction; -- 更新用户1的余额(获取行锁) update users set balance = balance - 100 where id = 1; -- 模拟长事务:等待60秒(不提交事务) select sleep(60); -- 事务b -- 开始事务 start transaction; -- 尝试更新用户1的余额(等待事务a释放锁) update users set balance = balance + 100 where id = 1;

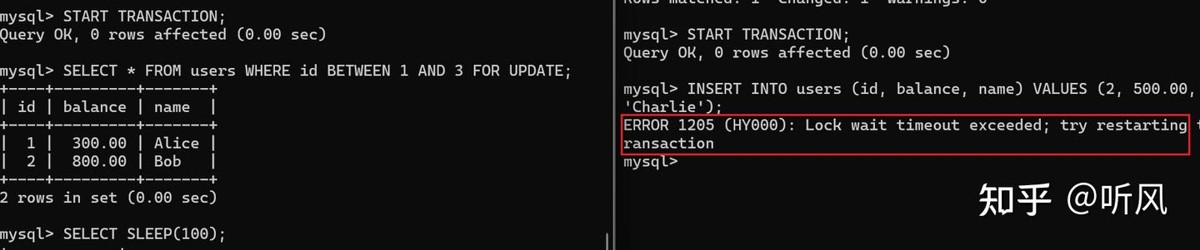
案例:长事务导致间隙锁不释放产生阻塞
-- 事务a -- 开始事务 start transaction; -- 执行范围查询(触发间隙锁) select * from users where id between 1 and 3 for update; -- 模拟长事务:等待60秒(不提交事务) select sleep(60); -- 事务b -- 开始事务 start transaction; -- 尝试插入间隙内的数据(等待事务a释放间隙锁) insert into users (id, balance, name) values (2, 500.00, 'charlie');
3. 索引缺失导致锁升级
未命中索引时,innodb 的行锁可能升级为表锁,扩大锁范围。
案例:全表扫描引发死锁
-- 无索引的查询 update users set balance = 0 where name = 'alice'; -- 无 name 索引
死锁原因:全表扫描导致对整张表加锁,其他事务修改任意行均被阻塞。
4. 间隙锁(gap lock)冲突
在可重复读(rr)隔离级别下,范围查询会锁定区间,导致插入冲突。
案例:间隙锁导致死锁
-- 事务a select * from orders where id between 10 and 20 for update; -- 加间隙锁 -- 事务b insert into orders (id, amount) values (15, 100); -- 尝试插入到间隙锁范围内
死锁原因:事务b的插入操作需要获取插入意向锁,但被事务a的间隙锁阻塞。
三、死锁的检测与处理
1. mysql 自动检测机制
innodb 通过 innodb_deadlock_detect(默认开启)自动检测死锁。检测到死锁时,会选择权重较小的事务回滚(如写入量少的事务),并抛出错误码 1213。
错误示例
2. 手动检测死锁
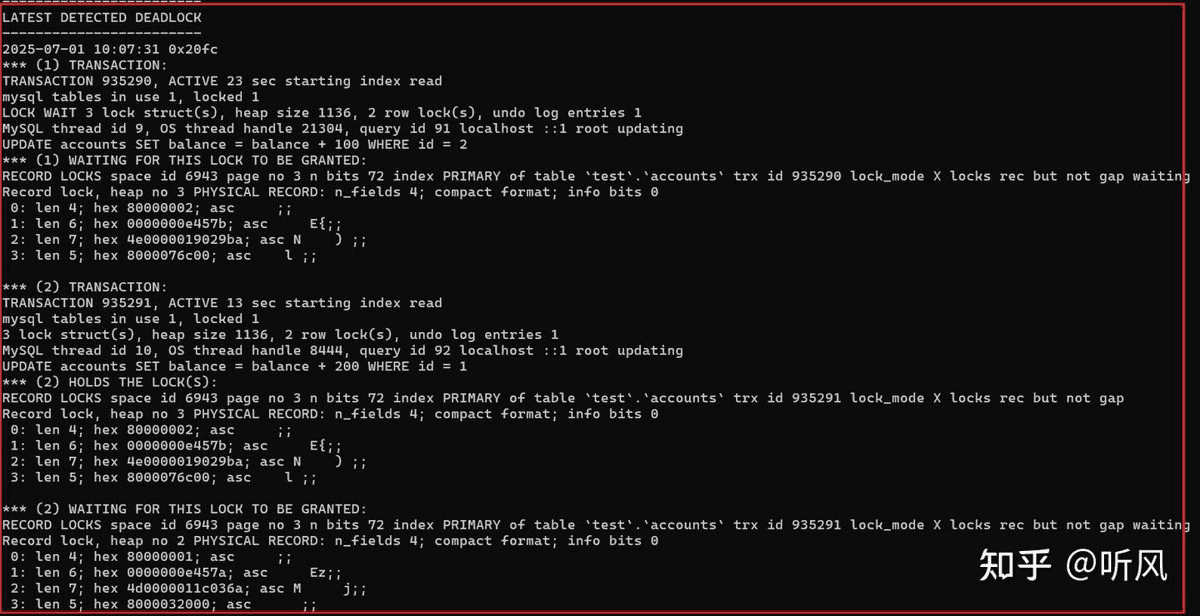
方法一:查看 show engine innodb status
show engine innodb status;
输出中包含 latest detected deadlock 部分,显示死锁事务的详细信息:
方法二:分析错误日志
mysql 错误日志中记录了死锁事件,可通过日志定位问题。
3. 死锁处理策略
(1)应用层重试
捕获死锁错误后,重试事务是常见的解决方案。例如:
try:
execute_transaction()
except deadlockerror:
retry_transaction()(2)设置锁超时
通过 innodb_lock_wait_timeout 设置锁等待超时时间(默认 50 秒),超时后自动回滚当前语句:
set innodb_lock_wait_timeout = 30; -- 单位:秒、
(3)开启主动死锁检测
这是mysql提供的死锁检测,如果这个机制发现了死锁,就会回滚其中的一个事务,让其他的事务得到执行,那么所有的事务就都解开了,设置的方法为:
innodb_deadlock_detect = on
(4)显式锁定资源
使用 select … for update 提前锁定所有需要的资源,避免后续争用:
-- 事务a start transaction; select * from accounts where id = 1 for update; select * from accounts where id = 2 for update; -- 按固定顺序锁定
四、死锁的预防策略
1. 事务设计优化
- 固定访问顺序:所有事务按相同顺序操作资源(如按 id 升序处理)。
- 拆分大事务:将长事务拆分为多个短事务,缩短持锁时间。
- 即时提交:避免事务内执行非数据库操作(如 api 调用)。
2. 索引优化
- 添加高频查询字段的索引:确保查询命中索引,避免全表扫描。
- 使用 explain 分析执行计划:确认索引是否生效。
3. 降低隔离级别
将事务隔离级别从 可重复读(rr) 调整为 读已提交(rc),减少锁范围和持有时间:
set transaction isolation level read committed;
4. 避免间隙锁冲突
- 避免范围查询:尽量使用精确查询(如 where id = 1)。
- 覆盖索引:确保查询字段在索引中,减少回表操作。
五、总结
mysql 死锁的本质是事务间的循环等待,其成因包括访问顺序不一致、长事务、索引缺失和间隙锁冲突。解决死锁的关键在于:
- 自动检测与回滚:依赖 mysql 的死锁检测机制。
- 事务设计优化:固定访问顺序、拆分长事务。
- 索引与锁策略:优化查询性能,减少锁范围。
- 应用层重试:捕获死锁错误并重试事务。
通过合理设计事务逻辑、优化索引和监控死锁日志,可以显著降低死锁发生率,提升数据库的稳定性和并发性能。
附录:死锁检测与处理工具
| 工具/方法 | 描述 |
|---|---|
| show engine innodb status | 查看最新死锁信息,包括事务 id 和 sql 语句。 |
| innodb_deadlock_detect | 控制死锁检测开关(默认开启)。 |
| innodb_lock_wait_timeout | 设置锁等待超时时间,超时后回滚当前语句。 |
| explain | 分析查询执行计划,确认索引是否命中。 |
| 错误日志 | 记录死锁事件,用于事后分析。 |
通过以上策略,开发者和数据库管理员可以高效应对 mysql 死锁问题,保障系统的高并发和稳定性。
到此这篇关于mysql死锁原因、检测与解决方案的文章就介绍到这了,更多相关mysql死锁原因及解决内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论