
一、发现问题
近期 oom 故障频发,一周内发生了 3 次。
但每次pod重启后,应用又一切正常;上个版本有代码发布的同学,排查了一遍新增代码,没找到可疑之处。
主要现象如下:
- 群里告警:grafana 告警,full gc 次数5分钟内超2次
- 群里告警:nacos、grpc 等中间件心跳连接超时
- 集群中对应服务:重启次数新增

grafana 告警 alertname: hk-5分钟内gc次数大于2次 状态: 告警❌ 内容: hk最近10分钟内的fullgc过多,当前值: 75.5,环境:prod,实例:10.20.56.36 应用: xxxx 时间: 2025-10-13 19:48:51 详情: 告警详情 来源: grafana 地址
查看 grafana 中 jvm 问题:

可为什么会导致重启?
看看得:jvm 内部 oom → 应用假死(线程卡死或频繁 full gc)→ 健康检查失败 → k8s 重启 pod
tips:另外一种 kill
oom killed pod:kubernetes 节点的 linux 内核 oom killer 杀掉了 pod 进程(可能是 jvm 进程),通常是容器的内存限制被突破。
排查此问题困难之处
既然知道是 oom,那就找对应 oom 生成 dump 文件,分析即可。
运维侧反馈来不及 dump 文件,就重启了,导致dump文件丢失。
最后,那我又是如何得到这个 dump 文件的?
既然运维侧不给力,那就只能靠平时多观察下这个应用的情况,一有怀疑情况就找对应运维同学。
恰好,被我抓到一次,直接坐到运维同学旁边,让其帮我上容器帮我 dump 一份数据。
二、定位问题
2.1 定位问题:dump 文件分析
生成 dump 文件:找运维同学操作,进入对应 pod 容器中,执行如下命令:
# 1、找到对应 pid: jps -l # 2、执行,只想 dump 活跃的对象: jcmd 12345 gc.heap_dump -all=false /tmp/heap_20240602.hprof
分析工具:使用的是 idea 自带的 profiler
直接打开对应的 dump 文件,展示如下:
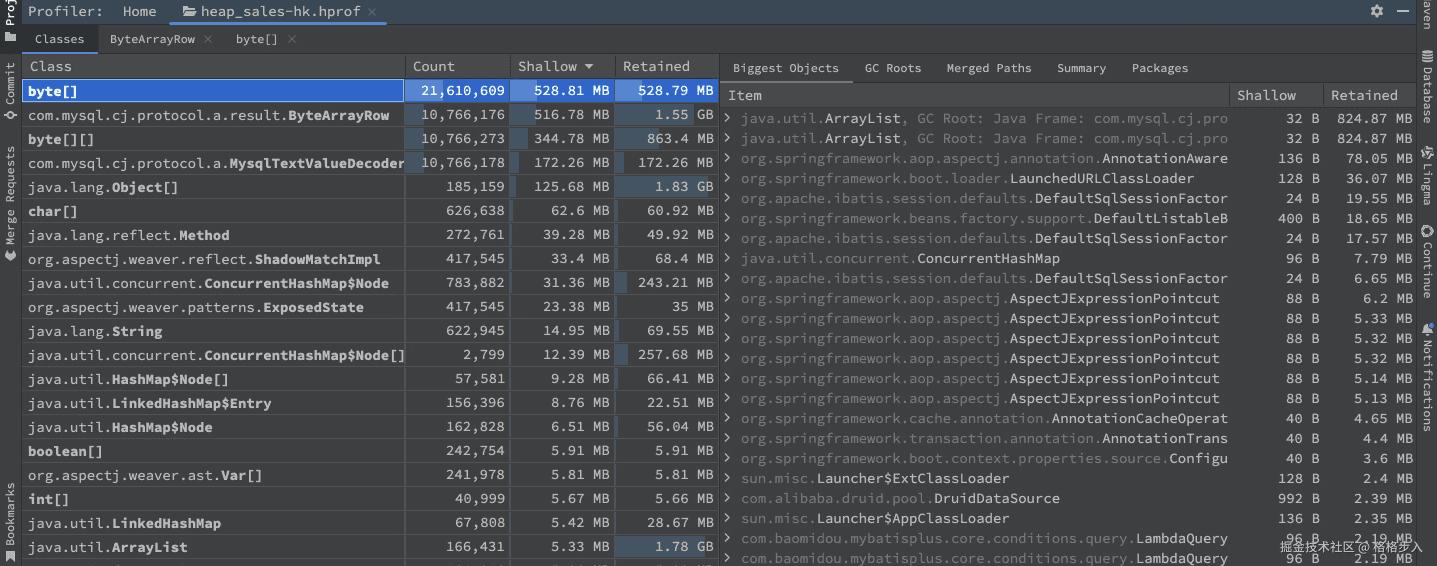
可以看到 byte[] 和 byte[][] 数据是 mysql 里的结果数据:

选择 byte[]:

图中的 gc root: java frame 表示:
- 在 java 的垃圾回收(gc)机制中,gc root 是一组特殊的对象引用,它们作为起点,gc 会从这些对象开始遍历引用链,找出所有可达对象。可达的对象不会被回收。
- java frame 指的是某个线程的栈帧(方法调用栈)中的局部变量或参数引用了这个对象。
gc root: java frame: com.mysql.cj.protocol.a.nativeprotocol.sendquerypacket(nativeprotocol.java:951)
这段话意思是:
- 这个
byte[]对象是被某个线程的栈上的局部变量引用着。 - 具体是在
com.mysql.cj.protocol.a.nativeprotocol类的sendquerypacket方法(第 951 行)中。 - 因为它在栈上被引用,所以 gc 无法回收它,直到这个方法执行结束并且栈帧被销毁。
找到一个具体的进入看下:

可以定位到某一个 sql,并将这个 sql 展示出来。
select amount, currency from risk_message
所有的线索都指向这个 sql 查询带出来大量的数据。
2.2 定位问题:具体代码
通过 sql 可以缩小范围,所有涉及这个表的代码,主要是 2 个接口:
- 入账审核列表:getinboundlist
- 汇总-入账成功金额:querysummary —— bug 点
代码如下:
list<riskmessage> list = riskmessagerepo.lambdaquery().select(riskmessage::getamount, riskmessage::getcurrency)
.eq(stringutils.isnotblank(clientid), riskmessage::getclientid, clientid)
.in(collectionutils.isnotempty(currencylist), riskmessage::getcurrency, currencylist)
.ge(objects.nonnull(orderstarttime), riskmessage::getvaluedate, orderstarttime)
.le(objects.nonnull(orderendtime), riskmessage::getvaluedate, orderendtime)
.list();这个功能主要汇总金额,但币种不同,得按照汇率换算出来,他这块实现步骤:
- 查询出所有符合条件的 <金额、币种> —— 问题点
- 在内存本地聚合
- 根据汇率进行换算,得出 usd 币种的金额
问题就在查询这块,没兜住,直接查询出 百万条 记录,导致内存在接下来的 30分钟 逐渐被占满。
- 时间范围没生效:没有强制时间范围
- 按币种先汇总:币种只有百来个,返回也只有百来行
直接让 ai 帮我排查这 2 个接口是否有问题:
claude-4-sonnet 回答道:

ai 的回答,居然是没有问题;当再次指出问题时,ai 又站起来了。
三、小结
排查过程中发现的一些事:
- http 请求调用时间长,不一定造成 oom,但一定是有问题的。
- mysql in 数量能调节,可以 1w+
- 现阶段的ai编程,不能完全相信,会绕进一些bug中,需要人工处理。
最后解决这个问题也比较简单:
- 强制选定范围
- 按照币种 sum,返回行数最多百来行
常见 full gc 触发原因:
| 触发原因 | 说明 | 典型特征 | 排查方法 |
|---|---|---|---|
| 老年代空间不足 | 大对象直接进入老年代,或晋升失败 | gc 日志显示 allocation failure,老年代使用率接近 100% | 查看 gc 日志中 old gen 使用率,分析对象生命周期 |
| 元空间(metaspace)不足 | 类加载过多,动态生成类(如反射、cglib) | gc 日志显示 metadata gc threshold | -xx:maxmetaspacesize 设置过小,或类加载泄漏 |
显式调用 system.gc() | 代码或第三方库调用 | gc 日志显示 system.gc() | gc 日志会显示 system.gc() 触发 |
| 直接内存不足 | directbytebuffer / netty 堆外内存耗尽 | 堆外内存不足时 jvm 会频繁 full gc 尝试释放 cleaner | -xx:maxdirectmemorysize,用 jcmd vm.native_memory summary 查看 |
| 大对象分配失败 | 超过 pretenuresizethreshold 直接进老年代 | gc 日志显示 promotion failed | 调整阈值或优化对象分配 |
| cms/g1 的 remark 阶段失败 | 并发回收失败,退化为 full gc | gc 日志显示 concurrent mode failure 或 to-space exhausted | 查看 gc 日志的 concurrent mode failure 或 to-space exhausted |
到此这篇关于一次oom排查解决过程的文章就介绍到这了,更多相关oom排查内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论