前言:python中的高效数据结构
在python的世界里,dict(字典)和set(集合)是两种极其重要且高效的数据结构。它们不仅在日常编程中被广泛使用,更是python性能优化的关键所在。本文将带您深入探索这两种数据结构的实现原理,揭开它们高效运作的神秘面纱。
一、字典(dict)的实现原理
1.1 哈希表:字典的基石
python的字典实现基于哈希表(hash table),这是一种通过键(key)快速访问值(value)的数据结构。哈希表的核心思想是将键通过哈希函数转换为数组的索引。

1.2 字典的内部结构
python字典的内部结构可以表示为:
| 字段 | 说明 |
|---|---|
ma_used | 已使用的条目数 |
ma_mask | 用于计算索引的掩码 |
ma_table | 存储条目的数组 |
ma_keys | 键对象数组 |
ma_values | 值对象数组 |
1.3 哈希冲突处理
当不同的键产生相同的哈希值时,就会发生哈希冲突。python使用开放寻址法来处理冲突:
- 线性探测:顺序查找下一个可用槽位
- 二次探测:使用二次方程计算下一个探测位置
# 简化的哈希表插入过程
def insert(hash_table, key, value):
index = hash(key) % len(hash_table)
while hash_table[index] is not none:
index = (index + 1) % len(hash_table) # 线性探测
hash_table[index] = (key, value)
1.4 字典的扩容机制
python字典会动态调整大小以保持高效:
- 当字典填充率达到2/3时触发扩容
- 新大小通常是当前大小的4倍(当字典较大时)或2倍(当字典较小时)
| 当前大小 | 新大小 |
|---|---|
| 8 | 16 |
| 16 | 32 |
| 32 | 64 |
| … | … |
1.5 字典的应用案例
案例1:高效统计词频
def word_count(text):
count = {}
for word in text.split():
count[word] = count.get(word, 0) + 1
return count
案例2:实现快速查找表
# 构建颜色名称到rgb值的映射
color_map = {
'red': (255, 0, 0),
'green': (0, 255, 0),
'blue': (0, 0, 255)
}
二、集合(set)的实现原理
2.1 集合的本质
python的集合本质上是一个只有键没有值的字典。它同样基于哈希表实现,但只关心键的存在与否。
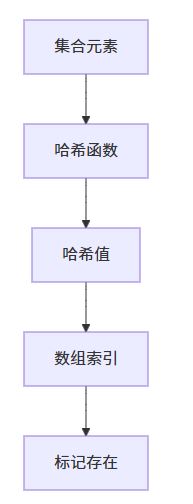
2.2 集合操作的时间复杂度
| 操作 | 平均时间复杂度 | 最坏情况 |
|---|---|---|
| 添加元素 | o(1) | o(n) |
| 删除元素 | o(1) | o(n) |
| 成员测试 | o(1) | o(n) |
| 并集 | o(len(s)+len(t)) | - |
| 交集 | o(min(len(s),len(t))) | - |
2.3 集合的应用案例
案例1:快速去重
def unique_elements(sequence):
return list(set(sequence))
案例2:高效成员测试
valid_users = {'alice', 'bob', 'charlie'}
def is_valid_user(username):
return username in valid_users # o(1)时间复杂度
三、dict与set的性能优化技巧
3.1 选择合适的键类型
- 使用不可变类型作为键(如字符串、数字、元组)
- 避免使用自定义对象作为键,除非正确实现了
__hash__和__eq__方法
3.2 预分配空间
# 预先知道大小时 large_dict = dict.fromkeys(range(1000000)) large_set = set(range(1000000))
3.3 字典视图的高效使用
d = {'a': 1, 'b': 2, 'c': 3}
# 高效迭代
for key in d: # 等同于 d.keys()
print(key, d[key])
# 高效查找共同键
common_keys = d.keys() & other_dict.keys()
四、内部实现进阶知识
4.1 python 3.6+的字典有序性
从python 3.6开始,字典保持了插入顺序,这是通过以下改变实现的:
- 使用紧凑的条目数组存储实际数据
- 维护一个单独的索引数组指向条目

4.2 内存布局对比
传统哈希表布局:
[哈希值, 键指针, 值指针] [哈希值, 键指针, 值指针] ...
python 3.6+布局:
索引数组: [索引1, 索引2, ...] 条目数组: [键1, 值1, 键2, 值2, ...]
这种布局减少了内存使用并提高了缓存局部性。
五、总结与思考
python的dict和set通过精妙的哈希表实现,提供了近乎o(1)时间复杂度的查找、插入和删除操作。理解它们的内部机制不仅有助于写出更高效的代码,还能在遇到性能问题时做出明智的优化决策。
| 特性 | dict | set |
|---|---|---|
| 实现基础 | 哈希表 | 哈希表 |
| 存储内容 | 键值对 | 仅键 |
| 有序性 | python 3.6+保持插入顺序 | python 3.6+保持插入顺序 |
| 主要用途 | 映射关系 | 唯一性检查、集合运算 |
正如python之父guido van rossum所说:“字典是python的基石”。掌握这些数据结构的内部原理,将使你成为更高效的python程序员。
以上就是一文详解python中dict与set的实现原理的详细内容,更多关于python dict与set实现原理的资料请关注代码网其它相关文章!






发表评论