在日常工作中,我们经常需要处理各种格式的数据。word文档以其灵活的排版能力,常用于报告和文档撰写,但当这些文档中包含大量表格数据时,将其用于进一步的数据分析或统计时,手动复制粘贴到excel无疑是一项耗时且易出错的任务。想象一下,面对几十甚至上百个word文档中的表格,这种重复性工作效率低下且令人沮丧。
幸运的是,python作为一种强大的自动化工具,能够完美解决这一痛点。本文将深入探讨如何利用python,结合 spire.doc for python 和 spire.xls for python 这两个库,高效、准确地将word文档中的表格数据提取并转换为可编辑的excel表格。通过自动化这一过程,您将能够显著提升工作效率,减少人为错误,并专注于更有价值的数据洞察。
环境准备与库安装
在开始之前,我们需要确保python环境已正确配置,并安装所需的库。本文假设您已经安装了python 3.x 版本。
首先,打开您的命令行工具(如cmd、powershell或terminal),然后使用pip命令安装spire.doc for python和spire.xls for python。这两个库是本次任务的核心,spire.doc for python负责读取和解析word文档内容,特别是识别和提取表格数据;而spire.xls for python则用于创建、写入和保存excel文件。
pip install spire.doc pip install spire.xls
安装完成后,您就可以在python脚本中导入和使用它们了。
word表格读取与数据提取
数据提取是整个转换过程的关键一步。我们将使用spire.doc for python来加载word文档,并遍历文档中的所有表格,逐一提取其内容。
以下是一个示例word文档:
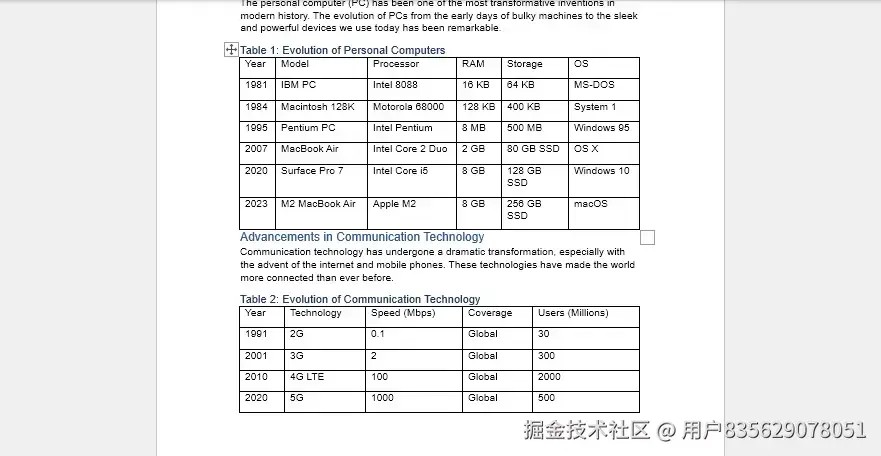
我们将编写代码来识别并提取这些数据。
from spire.doc import *
from spire.doc.common import *
def extract_tables_from_word(word_file_path):
"""
从word文档中提取所有表格数据。
返回一个列表,其中每个元素代表一个表格,表格内部是行的列表,行内部是单元格内容的列表。
"""
document = document()
document.loadfromfile(word_file_path)
all_tables_data = []
# 遍历文档中的所有节
for sec_index in range(document.sections.count):
section = document.sections.get_item(sec_index)
# 遍历节中的所有表格
for table_index in range(section.tables.count):
table = section.tables.get_item(table_index)
current_table_data = []
# 遍历表格中的所有行
for row_index in range(table.rows.count):
table_row = table.rows.get_item(row_index)
current_row_data = []
# 遍历行中的所有单元格
for cell_index in range(table_row.cells.count):
table_cell = table_row.cells.get_item(cell_index)
# 提取单元格文本,并保持单元格内原有段落结构
paras = [table_cell.paragraphs.get_item(i).text.rstrip('\r\n')
for i in range(table_cell.paragraphs.count)
if table_cell.paragraphs.get_item(i).text.strip()]
current_cell_data = "\n".join(paras)
current_row_data.append(current_cell_data)
current_table_data.append(current_row_data)
all_tables_data.append(current_table_data)
document.close()
return all_tables_data
# 假设您的word文档名为 'input.docx' 并且在当前目录下
word_file = "input.docx"
extracted_data = extract_tables_from_word(word_file)
# 打印提取的数据以供验证
for i, table_data in enumerate(extracted_data):
print(f"--- table {i + 1} data ---")
for row in table_data:
print(row)
控制台输出结果:

代码解析:
document()实例用于加载word文档。document.loadfromfile()方法加载指定路径的word文档。- 我们通过
document.sections迭代文档中的所有节,再通过section.tables迭代每个节中的所有表格。 - 对于每个表格,我们进一步迭代
table.rows获取行,然后迭代row.cells获取单元格。 cell.text.strip()用于获取单元格的纯文本内容,并移除可能存在的额外空白字符。- 所有提取的数据都存储在一个嵌套列表中,
all_tables_data是一个包含所有表格数据的列表,每个表格数据又是一个包含行数据的列表,行数据再包含单元格数据的列表。
数据写入excel与文件保存
提取到数据后,下一步就是将其写入excel文件。我们将使用spire.xls for python来创建新的excel工作簿,并将提取的数据逐一写入工作表。
from spire.xls import *
from spire.xls.common import *
def write_data_to_excel(extracted_data, excel_file_path):
"""
将提取的表格数据写入excel文件。
每个word表格将写入excel的一个新工作表。
"""
workbook = workbook()
# 清楚默认工作表
workbook.worksheets.clear()
# 如果没有提取到数据,则不创建excel文件
if not extracted_data:
print("没有从word文档中提取到任何表格数据。")
return
# 遍历所有提取的表格数据
for i, table_data in enumerate(extracted_data):
# 为每个表格创建一个新的工作表
sheet = workbook.worksheets.add(f"table_{i + 1}")
# 将表格数据写入工作表
for r_idx, row_data in enumerate(table_data):
for c_idx, cell_value in enumerate(row_data):
# excel的行和列索引从1开始
sheet.range[r_idx + 1, c_idx + 1].value = cell_value
# (可选)应用基本表格格式
# 如自动对齐列宽
sheet.allocatedrange.autofitcolumns()
# 保存excel文件
workbook.savetofile(excel_file_path, excelversion.version2016)
workbook.dispose()
print(f"数据已成功写入到 {excel_file_path}")
# 调用函数将数据写入excel
excel_file = "output.xlsx"
write_data_to_excel(extracted_data, excel_file)
写入效果:
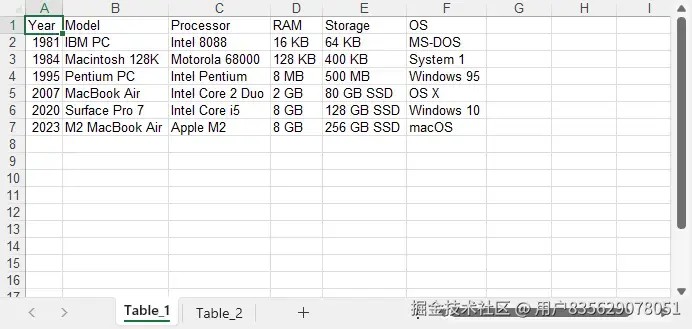
代码解析:
workbook()实例用于创建一个新的excel工作簿。- 我们遍历
extracted_data中的每个word表格。 - 对于第一个表格,我们使用
workbook.worksheets[0](默认的“sheet1”),并为其重命名;对于后续表格,则使用workbook.worksheets.add()创建新的工作表。 - 然后,我们遍历每个表格的行和单元格数据,使用
sheet.range[r_idx + 1, c_idx + 1].value = cell_value将数据写入excel单元格。注意,excel的行和列索引是从1开始的,所以需要+ 1。 workbook.savetofile()方法将工作簿保存为指定的excel文件,excelversion.version2016指定了保存的excel版本。
将上述两个部分的python代码片段整合在一起,您就拥有了一个完整的word表格到excel转换的自动化脚本。
总结与展望
通过本文的详细教程,我们学习了如何利用python结合 spire.doc for python 和 spire.xls for python 库,实现word文档中表格数据到excel表格的高效自动化转换。这一过程不仅省去了繁琐的手动复制粘贴,显著提升了数据处理效率,还最大程度地减少了人为错误的可能性。
这种自动化能力在多个领域都具有广泛的应用前景,例如:
- 报告数据整合:从多个word报告中提取关键数据,汇总到excel进行分析。
- 企业数据迁移:将旧的word文档中的结构化数据批量导入到新的数据库或系统。
- 日常办公自动化:简化重复性数据录入和格式转换工作,让您有更多时间专注于核心业务。
到此这篇关于python实现word表格自动化转为excel的文章就介绍到这了,更多相关python word表格转excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论