cpu的局部性原理
github地址
前言
在实际编程中,我们常会发现:
逻辑相同的代码,仅仅改变数据访问顺序,性能却可能相差数倍。
造成这种差异的根本原因,正是现代 cpu 的核心设计思想之一——局部性原理(locality principle)。
随着学习从“会写代码”走向“写出高性能代码”,我们会发现:
真正影响程序速度的,往往不是算法本身,而是内存访问模式与缓存命中率。
本文将围绕局部性原理展开,系统讲解:
- 什么是局部性原理
- 时间局部性与空间局部性的区别
- cpu 缓存如何利用局部性
- 代码访问方式为何会显著影响性能
帮助你理解程序性能与底层硬件之间的真实联系。
一、什么是局部性原理?
局部性原理(locality principle) 是指在程序运行过程中,所访问的指令和数据往往集中在较小的区域内,而不会随机分布在整个内存空间中。
换句话说:
程序的访问行为有“偏好”,更倾向于访问“刚刚访问过”或“靠近刚刚访问过”的内存区域。
这种规律来源于:
- 程序的控制结构(循环、函数调用)
- 数据结构的访问方式(数组、指针、链表等)
- 编译器生成代码的局部性优化
因此,cpu 可以利用这一规律,通过在缓存中保存近期访问的数据或指令,极大提高访问速度。
二、局部性原理的两种类型
1. 时间局部性(temporal locality)
如果一个数据项被访问过,那么它很可能在不久的将来再次被访问。
典型场景:
int sum = 0;
for (int i = 0; i < 1000; ++i)
sum += a[i];
- 变量
sum每次循环都会被访问(修改一次、读取一次)。 - 数组
a[i]的每个元素虽然只访问一次,但循环体代码在短时间内不断执行。
因此:
sum展现了强时间局部性。- 循环体指令也有时间局部性,因为 cpu 在短时间内反复执行同一段指令。
2. 空间局部性(spatial locality)
如果程序访问了某个地址的数据,那么它很可能在不久之后访问与该地址相邻的数据。
典型场景:
for (int i = 0; i < 1000; ++i)
sum += a[i];
- 当 cpu 访问
a[0]时,极有可能紧接着访问a[1]、a[2]…… - 因此 cpu 在加载内存块时,会预取(prefetch)一整块连续内存到缓存中(例如 64b 一行的 cache line)。
→ 这就是 空间局部性。
三、为什么需要局部性原理?
内存层次结构如下:
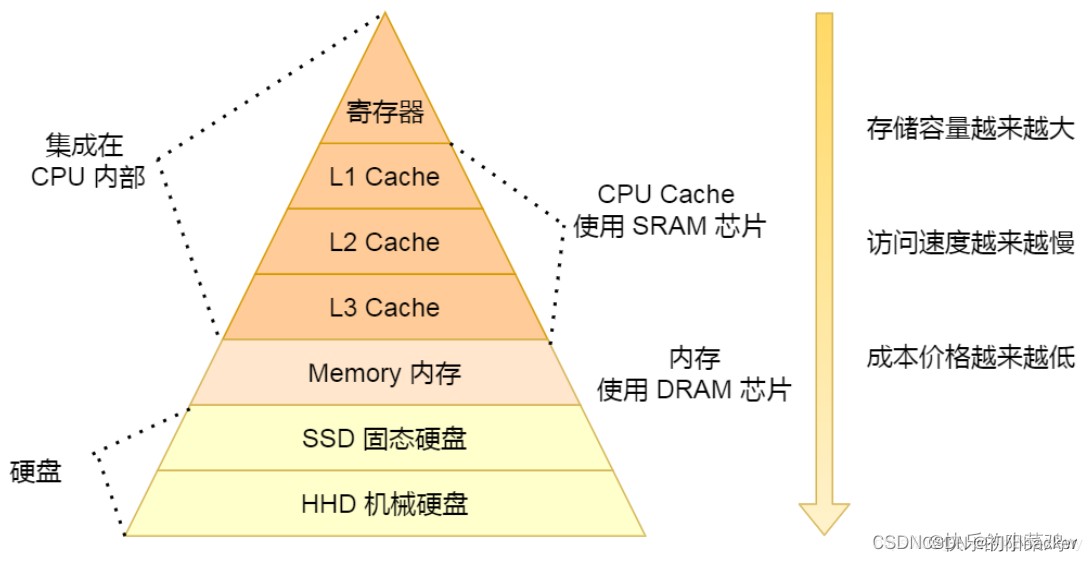
| 层级 | 存储类型 | 访问延迟 | 容量 | 特征 |
|---|---|---|---|---|
| 寄存器 | register | ~1ns | 极小 | 位于 cpu 内部 |
| 一级缓存 | l1 cache | ~2-4ns | kb 级 | 每个核心独享 |
| 二级缓存 | l2 cache | ~10ns | mb 级 | 每核心或共享 |
| 三级缓存 | l3 cache | ~30-40ns | 数十mb | 多核共享 |
| 主内存 | dram | ~100ns | gb 级 | 访问慢 |
| 硬盘/ssd | storage | >10⁶ns | tb 级 | 极慢 |
如果 cpu 每次都直接访问主内存(dram),效率会极低。
但由于局部性原理,cpu 可以:
- 把最近或附近的数据缓存到 l1/l2/l3 cache;
- 当再次访问时,直接命中缓存,访问速度提升数十倍到上百倍。
四、缓存设计如何利用局部性?
| 缓存机制 | 利用的局部性 | 示例 |
|---|---|---|
| cache line(缓存行) | 空间局部性 | 一次加载连续64字节数据 |
| cache 替换策略(lru) | 时间局部性 | 最近使用的优先保留 |
| prefetch(预取机制) | 空间局部性 | 预测程序下一个访问位置 |
| 分支预测(branch prediction) | 时间局部性 | 预测指令执行路径 |
五、代码层面如何体现局部性?
✅ 好的例子:行优先遍历(空间局部性强)
const int n = 1024;
int a[n][n];
int sum = 0;
for (int i = 0; i < n; ++i)
for (int j = 0; j < n; ++j)
sum += a[i][j];- 数组
a在内存中按行存储(c/c++ 默认行主序)。 - 连续访问
a[i][j]与a[i][j+1],命中率高。
❌ 坏的例子:列优先遍历(空间局部性差)
for (int j = 0; j < n; ++j)
for (int i = 0; i < n; ++i)
sum += a[i][j];
- 访问
a[i][j]与a[i+1][j]在内存中距离较远,缓存命中率低,性能显著下降。
六、局部性与性能优化的关系
| 优化目标 | 对应局部性 | 示例策略 |
|---|---|---|
| 提高 cache 命中率 | 时间 + 空间 | 减少随机访问,复用数据 |
| 编译器优化 | 时间 | 循环展开、函数内联 |
| 内存对齐 | 空间 | 避免跨 cache line 访问 |
| 数据结构优化 | 空间 | 结构体紧凑排列、soa 替代 aos |
| 多线程编程 | 时间 + 空间 | 减少伪共享(false sharing) |
七、直观示意图(逻辑图)
┌──────────────┐
│ cpu core │
└──────┬───────┘
│ 访问频繁数据
▼
┌──────────────┐
│ l1 cache │ ← 时间局部性:重复访问同一数据
└──────┬───────┘
│ 访问邻近数据
▼
┌──────────────┐
│ l2 cache │ ← 空间局部性:加载相邻数据块
└──────┬───────┘
│
▼
┌──────────────┐
│ dram │
└──────────────┘八、小结
| 项目 | 时间局部性 | 空间局部性 |
|---|---|---|
| 定义 | 近期访问的数据可能再次被访问 | 访问某地址的数据后,可能访问邻近地址 |
| 典型表现 | 循环变量、计数器、函数调用 | 数组遍历、顺序读取文件 |
| 缓存利用 | cache 替换策略 | cache line 预取 |
| 程序优化 | 减少重复计算、循环优化 | 顺序访问、内存对齐 |
九、延伸:局部性与现代 cpu 特性
| cpu 特性 | 依赖局部性 | 说明 |
|---|---|---|
| 分支预测(branch predictor) | 时间局部性 | 程序的分支往往重复同样的路径 |
| 指令预取(instruction prefetch) | 空间局部性 | 指令存储在连续地址中 |
| 超标量流水线(superscalar pipeline) | 时间局部性 | 指令流局部集中,可乱序执行 |
| cache 多级设计 | 时间 + 空间 | 快速响应最近/邻近访问请求 |
🔹总结一句话
cpu 的局部性原理 是计算机性能优化的核心思想之一:
程序访问有规律,缓存利用这规律。“刚访问的内容未来还会用到(时间局部性),
附近的内容也值得提前准备(空间局部性)。”
结语
局部性原理看似简单,却贯穿了整个现代计算机体系结构。
无论是多级缓存、预取机制、分支预测,还是我们在代码中进行的循环优化、数据布局调整,本质上都是在减少内存访问带来的等待时间。
当你理解了局部性原理,就能看清许多“性能差异”的本质:
顺序访问为什么更快?
结构体布局为何会影响效率?
答案,都藏在“局部性”之中。
希望本文能成为你理解计算机性能本质的一块基石,
在你深入操作系统、体系结构与高性能编程时,持续发挥作用。
到此这篇关于c++ cpu的局部性原理的两种类型解析的文章就介绍到这了,更多相关c++ cpu局部性原理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论