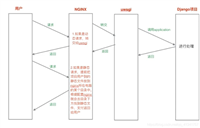
在微服务与高并发架构的江湖里,nginx不仅是流量的守门人,更是系统的“免疫系统”。然而,许多开发者对nginx健康检查的认知仍停留在“被动挨打”的阶段——只有当用户请求真正失败时,nginx才后知后觉地将故障节点剔除。这种“事后诸葛亮”式的策略,在生产环境中往往意味着宝贵的用户体验被牺牲。
今天,我们要彻底打破这种被动局面,深入剖析如何利用主动健康检查,赋予nginx未卜先知的能力,构建真正坚如磐石的高可用负载均衡层。
一、 痛点直击:被动检查的“原罪”
nginx开源版原生自带的ngx_http_upstream_module模块,提供的是一种被动健康检查。其核心机制依赖于max_fails和fail_timeout两个参数。
- 工作原理:当nginx将请求转发给后端某节点失败达到
max_fails次(默认1次),便会在fail_timeout时间内将该节点标记为“不可用”,之后才会将流量切换到健康节点。 - 致命缺陷:
- 首个用户成“炮灰”:故障发生后的第一个请求必定会失败,因为nginx必须先“试错”才能发现问题。
- 脑裂风险:如果后端服务只是僵死(端口还在监听),tcp连接能建立,nginx会认为连接成功,继续疯狂转发请求,直到堆积如山。
- 恢复迟钝:节点恢复后,需等待探测请求成功才能重新上线,这期间流量可能被无谓地浪费在其他节点上。
简而言之,被动检查是“以用户反馈为信号”,而我们需要的是“以系统自检为信号”。
二、 核心武器:nginx_upstream_check_module
要实现真正的主动健康检查,我们必须请出神器——第三方模块 nginx_upstream_check_module(由淘宝tengine团队开发并开源)。它允许nginx作为一个独立的“探针”,按照预设频率主动向后端发送心跳包,根据响应状态实时动态调整负载均衡策略。
1. 安装与部署
这一步是门槛所在。由于该模块未包含在官方源码中,必须重新编译nginx:
# 1. 下载nginx源码及对应版本的check模块补丁 wget https://nginx.org/download/nginx-1.26.1.tar.gz wget https://github.com/yaoweibin/nginx_upstream_check_module/archive/refs/tags/v0.4.0.tar.gz # 2. 解压并打补丁(关键步骤) tar -zxvf nginx-1.26.1.tar.gz tar -zxvf v0.4.0.tar.gz cd nginx-1.26.1 patch -p1 < ../nginx_upstream_check_module-0.4.0/check_1.20.1+.patch # 3. 编译安装(带模块) ./configure --prefix=/usr/local/nginx --add-module=../nginx_upstream_check_module-0.4.0 make && make install
注意:版本匹配是生死线,补丁版本必须与nginx主版本严格对应,否则编译必报错。
2. 核心配置解析
安装完成后,你将获得一把“尚方宝剑”——check指令。以下是生产级推荐配置:
upstream detayun_server {
server 127.0.0.1:8000 weight=1;
server 192.168.31.108:80 weight=2;
# 主动健康检查核心配置
check interval=3000 rise=2 fall=3 timeout=1000 type=http;
# 关键!动态host头,避免硬编码导致的路由错误
check_http_send "get /healthcheck http/1.0\r\nhost: $proxy_host\r\n\r\n";
# 定义存活标准:2xx/3xx均视为健康
check_http_expect_alive http_2xx http_3xx;
# (可选)共享内存大小,服务器多时需调大
check_shm_size 10m;
}
参数深度解码:
interval=3000:每3秒探测一次。太频繁会压垮网络,太迟钝会影响容灾,3-5秒是黄金平衡点。rise=2:连续2次成功才恢复上线。防止网络抖动导致的“闪断”误判。fall=3:连续3次失败才剔除。给后端服务留出短暂gc或重启的喘息空间,避免误杀。check_http_send:这里必须使用$proxy_host变量!如果你写死host: 127.0.0.1:8000,当nginx检查192.168.31.108时,后端服务收到的host头却是本地回环地址,极大概率返回404,导致nginx误以为后端挂了。
三、 进阶实战:从“能用”到“好用”
1. 专用健康检查接口
不要直接检查首页(/)!首页可能包含大量动态资源或图片,检查成本高且容易因非核心元素加载失败而误判。
最佳实践:在后端应用中写一个极简的/healthz或/status接口,仅返回200 ok,甚至不需要经过业务逻辑层,直接由web服务器(如nginx自身)返回,耗时控制在10ms以内。
2. 混合检查策略
对于核心交易链路,仅检查http状态码是不够的(数据库连接池爆了也可能返回200)。此时可采用tcp+http双重保险:
# 先通过tcp握手确保端口活着 check port=80 type=tcp; # 再通过http检查业务逻辑 check_http_send "get /api/v1/health http/1.0\r\n\r\n";
或者利用check_fastcgi_param等指令深入检测php/java应用的内部状态。
3. 状态可视化监控
配置check_status指令,暴露一个监控页面:
location /status {
check_status;
access_log off;
# 强烈建议设置ip白名单,防止敏感信息泄露
allow 192.168.0.0/16;
deny all;
}
访问该页面,你能清晰看到每个节点的rise/fall计数、当前状态(up/down)以及权重,让运维不再是黑盒操作。
四、 避坑指南与高可用哲学
- 防火墙别“自 杀”:确保nginx服务器的出站规则允许访问后端的检查端口,很多故障竟是防火墙拦截了健康检查包导致的。
- 资源隔离:健康检查会消耗少量cpu和带宽,在万台服务器规模下,需调大
check_shm_size,避免共享内存溢出导致检查失效。 - 非抢占模式:在keepalived+nginx的双机热备架构中,建议结合
vrrp_script脚本调用nginx的健康检查接口。如果后端全挂,应主动降低master节点的优先级(如减去30分),让备用机接管,而不是死撑。
结语
nginx的主动健康检查,不仅仅是几行配置,它是**“防御性编程”**思想在基础设施层的体现。它将故障拦截在用户无感知的阶段,把“服务治理”的能力下沉到了网关层。
在2025年的今天,面对日益复杂的分布式系统,如果你还在依赖被动的max_fails,无异于在雷区蒙眼狂奔。立刻行动起来,编译模块、配置探针、优化策略,让你的nginx拥有一双“透 视眼”,在流量洪峰中为你的业务保驾护航!
以上就是nginx主动健康检查的实战指南的详细内容,更多关于nginx主动健康检查的资料请关注代码网其它相关文章!




发表评论