在python+fastapi的后端项目中,我们往往很多时候需要对数据进行相关的处理,本篇随笔介绍在python+fastapi项目中使用sqlalchemy操作数据的几种常见方式。
使用 fastapi, sqlalchemy, pydantic构建后端项目的时候,其中数据库访问采用sqlalchemy 的异步方式处理。一般我们在操作数据库操作的时候,采用基类继承的方式减少重复代码,提高代码复用性。不过我们在分析sqlalchemy的时候,我们可以简单的方式来剖析几种常见的数据库操作方式,来介绍sqlalchemy的具体使用。
1、sqlalchemy介绍
sqlalchemy 是一个功能强大且灵活的 python sql 工具包和对象关系映射(orm)库。它被广泛用于在 python 项目中处理关系型数据库的场景,既提供了高级的 orm 功能,又保留了对底层 sql 语句的强大控制力。sqlalchemy 允许开发者通过 python 代码与数据库进行交互,而无需直接编写 sql 语句,同时也支持直接使用原生 sql 进行复杂查询。下面是sqlalchemy和我们常规数据库对象的对应关系说明。
| engine | 连接对象 | 驱动引擎 |
| session | 连接池 | 事务 由此开始查询 |
| model | 表 | 类定义 |
| column | 列 | |
| query | 若干行 | 可以链式添加多个条件 |
在使用sqlalchemy时,通常会将其与数据库对象对应起来。
sqlalchemy: 使用 table 对象或 declarative base 中的类来表示。
对应关系: 数据库中的每一个表对应于sqlalchemy中的一个类,该类继承自 declarative_base()。
from sqlalchemy import column, integer, string, create_engine
from sqlalchemy.ext.declarative import declarative_base
base = declarative_base()
class user(base):
__tablename__ = 'users' # 数据库表名
id = column(integer, primary_key=true)
name = column(string)
email = column(string)
数据库列 (database column): 使用 column 对象来表示。每个数据库表中的列在sqlalchemy中表示为 column 对象,并作为类的属性定义。
id = column(integer, primary_key=true) name = column(string(50))
数据库行 (database row): 每个数据库表的一个实例(对象)代表数据库表中的一行。在sqlalchemy中,通过实例化模型类来表示数据库表中的一行。
new_user = user(id=1, name='john doe', email='john@example.com')
主键 (primary key) :使用 primary_key=true 参数定义主键。
id = column(integer, primary_key=true)
外键 (foreign key): 使用 foreignkey 对象来表示。
from sqlalchemy import foreignkey
from sqlalchemy.orm import relationship
class address(base):
__tablename__ = 'addresses'
id = column(integer, primary_key=true)
user_id = column(integer, foreignkey('users.id'))
user = relationship('user')
关系 (relationships): 使用 relationship 对象来表示。数据库中表与表之间的关系在sqlalchemy中通过 relationship 来定义。
addresses = relationship("address", back_populates="user")
2、常规的单表处理
下面我们通过异步处理的方式,介绍如何在单表中操作相关的数据库数据。
async def get(self, db: asyncsession, id: any) -> any:
"""根据主键获取一个对象"""
if isinstance(id, str):
query = select(self.model).filter(func.lower(self.model.id) == id.lower())
else:
query = select(self.model).filter(self.model.id == id)
result = await db.execute(query)
item = result.scalars().first()
return item
如果我们需要强制对外键的类型进行匹配(如对于postgresql的严格要求,数据比较的类型必须一致),那么我们需要在基类或者crud类初始化的时候,获得对应的主键类型。
class basecrud(generic[modeltype, primarykeytype, pagedtotype, dtotype]):
"""
基础crud操作类,传入参数说明:
* `modeltype`: sqlalchemy 模型类
* `primarykeytype`: 限定主键的类型
* `pagedtotype`: 分页查询输入类
* `dtotype`: 数据传输对象类,如新增、更新的单个对象dto
"""
def __init__(self, model: type[modeltype]):
"""
数据库访问操作的基类对象(crud).
* `model`: a sqlalchemy model class
"""
self.model = model # 模型类型
# 运行期获取主键字段类型
pk_column = inspect(model).primary_key[0]
self._pk_type = pk_column.type.python_type # int / str
因此对于单表的get方法,我们修改下,让他匹配主键的类型进行比较,这样过对于严格类型判断的postgresql也正常匹配了。
async def get(self, db: asyncsession, id: primarykeytype) -> optional[modeltype]:
"""根据主键获取一个对象"""
#对id的主键进行类型转换,self._pk_type在构造函数的初始化中获取
try:
id = self._pk_type(id)
except exception:
raise valueerror(f"invalid primary key type: {id}")
if isinstance(id, str):
query = select(self.model).filter(func.lower(self.model.id) == id.lower())
else:
query = select(self.model).filter(self.model.id == id)
result = await db.execute(query)
item = result.scalars().first()
return item
对于删除的数据,我们也可以类似的处理对比进行了。
from sqlalchemy.orm import session, query
from sqlalchemy.ext.asyncio import asyncsession
from sqlalchemy import delete as sa_delete, update as sa_update
async def delete_byid(self, db: asyncsession, id: primarykeytype) -> bool:
"""根据主键删除一个对象
:param id: 主键值
"""
#对id的主键进行类型转换,self._pk_type在构造函数的初始化中获取
try:
id = self._pk_type(id)
except exception:
raise valueerror(f"invalid primary key type: {id}")
del_query: sa_delete
if isinstance(id, str):
del_query = sa_delete(self.model).where(
func.lower(self.model.id) == id.lower()
)
else:
del_query = sa_delete(self.model).where(self.model.id == id)
result = await db.execute(del_query)
await db.commit()
return result.rowcount > 0
对于提供多条件的查询或者过滤,我们可以使用where函数或者filter函数,在 sqlalchemy 中,select(...).where(...) 和 select(...).filter(...) 都用于构造查询条件,如下所示等效。
query = select(self.model).where(self.model.id == id) query = select(self.model).filter(self.model.id == id)
我们可以通过sqlalchemy的and_和or_函数来进行组合多个条件。
from sqlalchemy import ( table,column,and_,or_,asc,desc,select,func,distinct,text, integer)
....
match expression:
case "and":
query = await db.execute(
select(self.model)
.filter(and_( * where_list))
.order_by(*order_by_list)
)
case "or":
query = await db.execute(
select(self.model).filter(or_( *where_list)) .order_by(*order_by_list)
)
python的sqlalchemy提供 instrumentedattribute 对象来操作多个条件,如我们对于一些多条件的处理,可以利用它来传递多个参数。
async def get_all_by_attributes(
self, db: asyncsession, *attributes: instrumentedattribute, sorting: str = ""
) -> list[modeltype] | none:
"""根据列名称和值获取相关的对象列表
:param sorting: 格式:name asc 或 name asc,age desc
:param attributes: sqlalchemy instrumentedattribute objects,可以输入多个条件
例子:user.id != 1 或者 user.username == "johndoe"
"""
order_by_list = parse_sort_string(sorting, self.model)
query = select(self.model).filter(and_(*attributes)).order_by(*order_by_list)
result = await db.execute(query)
return result.scalars().all()
例如,对于 模型 material 对象,我们对它进行多个条件的查询处理,如下所示,红色部分为 *attributes: instrumentedattribute 参数。
items = await super().get_all_by_attributes(
db,
material.id == vercol.id,
material.vercol == vercol.vercol,
material.ischecked == 0,
material.status == 0,
)
同样我们可以利用它来获取数量,或者判断多条件的记录是否存在。
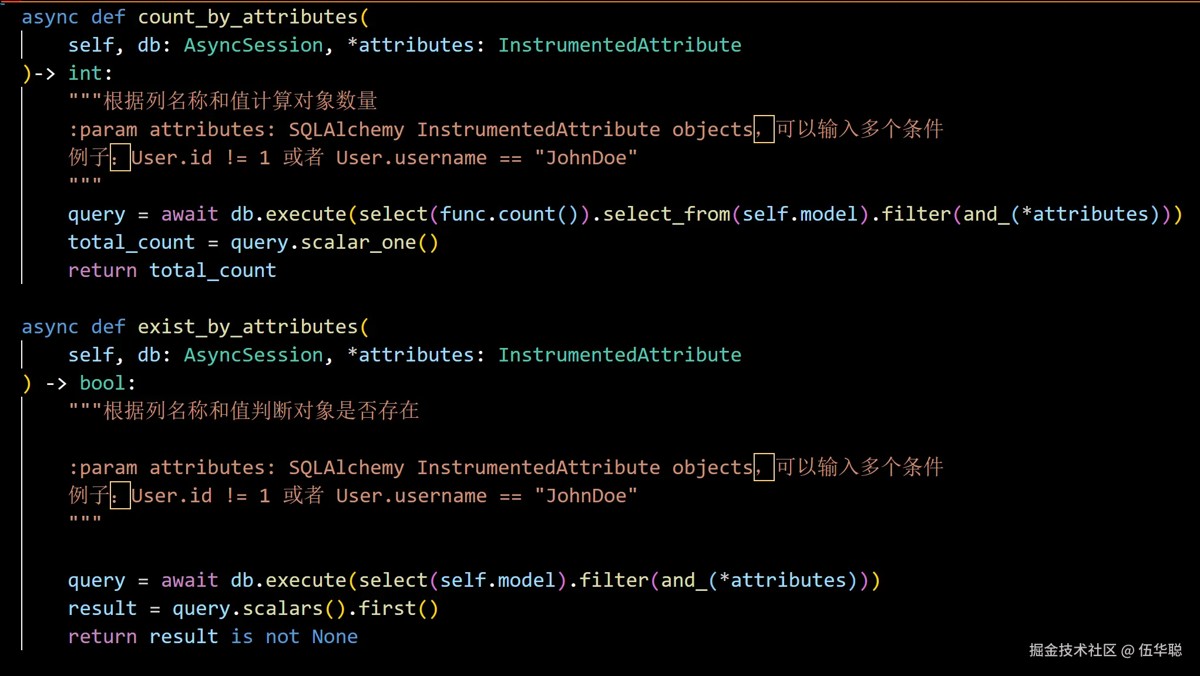
在数据插入或者更新的操作中,我们可以接受对象类型或者字典类型的参数对象,因此方法如下所示。
async def update(self, db: asyncsession, obj_in: dtotype | dict[str, any]) -> bool:
"""更新对象
:param obj_in: 对象输入数据,可以是 dto 对象或字典
"""
try:
if isinstance(obj_in, dict):
obj_id = obj_in.get("id")
if obj_id is none:
raise valueerror("id is required for update")
update_data = obj_in
else:
obj_id = obj_in.id
# update_data = vars(obj_in)
update_data = obj_in.model_dump(exclude_unset=true)
query = select(self.model).filter(self.model.id == obj_id)
result = await db.execute(query)
db_obj = result.scalars().first()
if db_obj:
# 更新对象字段
for field, value in update_data.items():
# 跳过以 "_" 开头的私有属性
if field.startswith("_"):
continue
setattr(db_obj, field, value)
# 处理更新前的回调处理
self.on_before_update(update_data, db_obj) # 提交事务
await db.commit()
return true
else:
return false
except sqlalchemyerror as e:
self.logger.error(f"update 操作出现错误: {e}")
await db.rollback() # 确保在出错时回滚事务
return false
我们在插入或者更新数据的时候,一般会默认更新一些字段,如创建人,创建日期、编辑人,编辑日期等信息,我们可以把它单独作为一个可以给子类重写的函数,基类做一些默认的处理。
def on_before_update(self, update_data: dict[str, any], db_obj: modeltype) -> none:
"""更新对象前的回调函数,子类可以重写此方法
可通过 setattr(db_obj, field, value) 设置字段值
"""
setattr(db_obj, "edittime", datetime.now())
user :currentuserins = get_current_user()
if user:
setattr(db_obj, "editor", user.fullname)
setattr(db_obj, "editor_id", user.id)
setattr(db_obj, "company_id", user.company_id)
setattr(db_obj, "companyname", user.companyname)
有时候,如果我们需要获取某个字段非重复的列表,用来做为动态下拉列表的数据,那么我们可以通过下面函数封装下。
async def get_field_list(self, db: asyncsession, field_name: str) -> iterable[str]:
"""获取指定字段值的唯一列表
:param field_name: 字段名称
"""
field = getattr(self.model, field_name)
query = select(distinct(field))
result = await db.execute(query)
return result.scalars().all()
3、多表联合的处理操作
多表操作,也是我们经常碰到的处理方式,如对于字典类型和字典项目,他们是两个表,需要联合起来获取数据,那么就需要多表的联合操作。
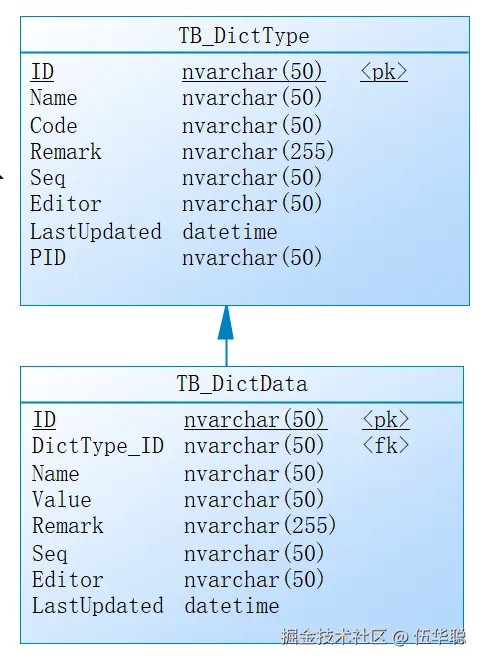
如下是字典crud类中,联合字典类型获取数据的记录处理。
async def get_dict_by_typename(self, db: asyncsession, dicttype_name: str) -> dict:
"""根据字典类型名称获取所有该类型的字典列表集合"""
result = await db.execute(
select(self.model)
.join(dicttype, dicttype.id == self.model.dicttype_id) # 关联字典类型表
.filter(dicttype.name == dicttype_name) # 过滤字典类型名称
.order_by(dictdata.seq) # 排序
)
items = result.scalars().all()
dict = {}
for info in items:
if info.name not in dict:
dict[info.name] = info.value
return dict
如果我们需要对某个表的递归获取树列表,可以如下处理
async def get_tree(self, db: asyncsession, pid: str) -> list[dicttype]:
"""获取字典类型一级列表及其下面的内容"""
# 使用三元运算符将 pid 设为 "-1"(如果 pid 是 null 或空白)或保持原值
pid = "-1" if not pid or pid.strip() == "" else pid
result = await db.execute(
select(self.model)
.filter(self.model.pid == pid)
.options(selectinload(dicttype.children))
)
nodes = result.scalars().all()
return nodes
我们来假设用户和文章的示例表结构(orm 模型,如下所示。
class user(base):
__tablename__ = "users"
id = column(integer, primary_key=true, index=true)
name = column(string)
email = column(string)
articles = relationship("article", back_populates="author")
class article(base):
__tablename__ = "articles"
id = column(integer, primary_key=true, index=true)
title = column(string)
content = column(text)
user_id = column(integer, foreignkey("users.id"))
author = relationship("user", back_populates="articles")
我们可以通过下面函数处理获得相关的记录集合。
async def get_user_articles(db: asyncsession):
stmt = (
select(user, article)
.join(article, article.user_id == user.id)
)
result = await db.execute(stmt)
return result.all() # [ (user(), article()), . ..]
如果需要可以使用outer_join函数处理
async def get_users_with_articles(db: asyncsession):
stmt = (
select(user, article)
.outerjoin(article, article.user_id == user.id)
)
result = await db.execute(stmt)
return result.all() # 用户即便没有文章也会出现
如果我们需要获取有文章的所有用户,如下所示。
async def get_users_with_articles(db: asyncsession):
stmt = select(user).options(selectinload(user.articles)) # 自动 load 关联
result = await db.execute(stmt)
return result.scalars().all()
selectinload 会执行两次 sql,但效率高,不会产生笛卡尔积,非常适合集合查询。
多表链式 join的处理,可以获得两个表的不同信息进行组合。
async def get_articles_with_author(db: asyncsession):
stmt = (
select(article.title, user.name.label("author"))
.join(user, article.user_id == user.id)
)
rows = await db.execute(stmt)
return rows.mappings().all() # 以 dict 形式返回 [{'title':..., 'author':...}]
带筛选条件与分页的处理实现,如下所示
async def search_articles(db: asyncsession, keyword: str, page: int = 1, size: int = 10):
stmt = (
select(article, user.name.label("author"))
.join(user)
.filter(article.title.contains(keyword))
.offset((page - 1) * size)
.limit(size)
)
result = await db.execute(stmt)
return result.mappings().all()
对于权限管理系统来说,一般有用户、角色,以及用户角色的中间表,我们来看看这个在sqlalchemy最佳实践是如何的操作。
from sqlalchemy import table, column, integer, foreignkey
from sqlalchemy.orm import relationship, mapped, mapped_column
from database import base
# --- 中间表写法 ---
role_user = table(
"role_user",
base.metadata,
column("user_id", foreignkey("users.id"), primary_key=true),
column("role_id", foreignkey("roles.id"), primary_key=true)
)
class user(base):
__tablename__ = "users"
id: mapped[int] = mapped_column(primary_key=true)
username: mapped[str] = mapped_column()
roles: mapped[list["role"]] = relationship(
secondary=role_user,
back_populates="users",
lazy="selectin"
)
class role(base):
__tablename__ = "roles"
id: mapped[int] = mapped_column(primary_key=true)
name: mapped[str] = mapped_column()
users: mapped[list[user]] = relationship(
secondary=role_user,
back_populates="roles",
lazy="selectin"
)
在 sqlalchemy 声明多对多关系时,secondary 参数既可以填 字符串形式的表名,也可以填 已经定义好的中间表对象(table 对象)。
① econdary="role_user" —— 使用字符串表名
roles = relationship("role", secondary="role_user", back_populates="users")
② secondary=role_user —— 传入中间表对象(推荐方式)
role_user = table(
"role_user",
base.metadata,
column("user_id", foreignkey("users.id"), primary_key=true),
column("role_id", foreignkey("roles.id"), primary_key=true)
)
roles = relationship("role", secondary=role_user, back_populates="users")
对于如果获取对应角色的用户记录,我们可以通过下面方式获取(通过连接中间表的方式)
async def get_users_by_role(db: asyncsession, role_id: int) -> list[user]:
stmt = (
select(user)
.join(role_user, role_user.c.user_id == user.id)
.where(role_user.c.role_id == role_id)
)
result = await db.execute(stmt)
return result.scalars().all()
也可以下面的方式进行处理(使用 relationship any()),效果是一样的。
select(user).filter(user.roles.any(id=role_id))
如果需要写入用户、角色的关联关系,我们可以使用下面方法来通过中间表进行判断并写入记录。
from sqlalchemy import select, insert
async def add_users_to_role(db: asyncsession, role_id: int, user_ids: list[int]):
# 1️⃣ 查询已有关联 user_id
stmt = select(role_user.c.user_id).where(role_user.c.role_id == role_id)
res = await db.execute(stmt)
existing_user_ids = {row[0] for row in res.fetchall()}
# 2️⃣ 过滤出新的 user_id
new_user_ids = [uid for uid in user_ids if uid not in existing_user_ids]
if not new_user_ids:
return 0 # 没有新增
# 3️⃣ 批量插入
values = [{"user_id": uid, "role_id": role_id} for uid in new_user_ids]
stmt = insert(role_user).values(values)
await db.execute(stmt)
await db.commit()
return len(new_user_ids)
如果只是单个记录的插入,可以利用下面的方式处理。
from sqlalchemy import select, insert
async def add_user_to_role(db: asyncsession, role_id: int, user_id: int) -> bool:
# 1️⃣ 检查是否已存在关联
stmt = select(role_user).where(
role_user.c.role_id == role_id,
role_user.c.user_id == user_id
)
res = await db.execute(stmt)
exists = res.first()
if exists:
return false # 已存在,不再插入
# 2️⃣ 插入记录
stmt = insert(role_user).values(user_id=user_id, role_id=role_id)
await db.execute(stmt)
await db.commit()
return true
以上就是对于在python+fastapi的后端项目中使用sqlalchemy操作数据的几种常见方式,包括单表处理,多表关联、中间表的数据维护和定义等内容,是我们在操作常规数据的时候,经常碰到的几种方式。
到此这篇关于python使用sqlalchemy操作数据的常见方式详解的文章就介绍到这了,更多相关python sqlalchemy操作数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论