在mongodb存在另一种集群就是mongodb的分片技术。通过使用分片可以满足mongodb数据量大量增长的需求。当mongodb存储海量的数据时,一台mongodb服务器可能不能满足存储数据的要求,也可能不足以提供可接受的读写吞吐量。mongodb为了解决这一系列的问题提出了将数据分割存储在多台服务器上,使得数据库系统能存储和处理更多的数据,以实现数据的分布式存储。这就是mongodb的分片。
提示:单个mongodb复制集中的节点不能超过12个节点。
因此复制集从本质上并不能解决数据海量存储的问题。
一、 mongodb分片的架构
mongodb分片的架构需要依赖mongodb的复制集为基础来实现,下图展示了分片的体系架构。
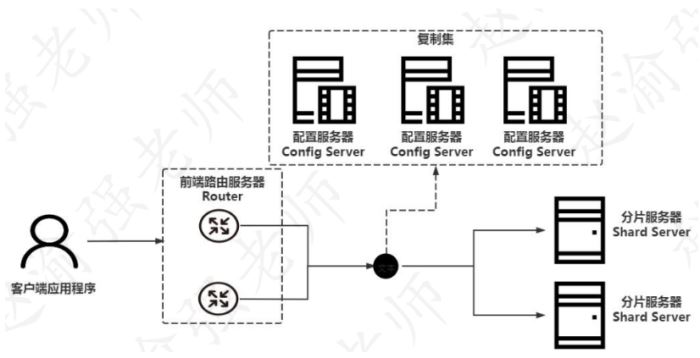
从图中可以看出,mongodb的分片主要包含以下几个组成的部分:
- 前端路由服务器:router,客户端应用程序从router接入mongodb分片集群。router可以让分片集群看上去像一个单一的数据库。router通过mongos的命令来启动。
- 配置服务器:config server,负责存储mongodb分片的元信息以及后端的分片服务器信息。从mongodb 3.4的版本开始,config server必须配置成一个复制集的形式。
- 分片服务器:shard server,负责存储实际的数据块。在实际生产环境中一个shard server可以由几台服务器组成一个复制集,从而防止主机单点故障造成数据的丢失。分片服务器也必须是一个复制集的形式。
点击这里查看视频讲解:【赵渝强老师】mongodb的分布式存储架构
二、 【实战】部署mongodb分片
在了解到了mongodb分片的架构与组成以后,下表列举了mongodb分片中的各个节点信息。
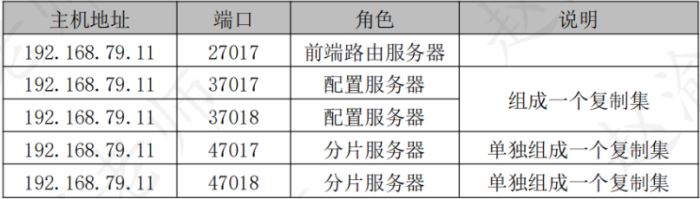
提示:表中列举的的信息是mongodb分片架构的最简信息。
例如这里的前端路由服务器只使用了一个节点来实现,
在实际的生产环境中可以搭建多个节点前端路由服务器。
下面通过具体的步骤来演示如何部署一个mongodb的分片。
(1)创建各个节点数据的存储路径。
mkdir -p /data/27017 mkdir -p /data/37017 mkdir -p /data/37018 mkdir -p /data/47017 mkdir -p /data/47018
(2)创建前端路由服务器的配置信息文件/data/27017/mongos.conf
port=27017 fork=true logpath=/data/27017/mongos.log configdb=myshardingconfig/127.0.0.1:37017,127.0.0.1:37018 其中:configdb用于指定配置服务器的地址。
(3)创建第一个配置服务器的配置信息文件/data/37017/mongo_configsvr_37017.conf
dbpath=/data/37017 port=37017 fork=true logpath=/data/37017/configsvr37017.log replset=myshardingconfig configsvr=true 其中:configsvr=true,表示这是一台配置服务器。
(4)创建第一个配置服务器的配置信息文件/data/37018/mongo_configsvr_37018.conf
dbpath=/data/37018 port=37018 fork=true logpath=/data/37018/configsvr37018.log replset=myshardingconfig configsvr=true
(5)创建第一个分片服务器的配置信息文件/data/47017/mongo_shardsvr_47017.conf
dbpath=/data/47017 port=47017 fork=true logpath=/data/47017/shardsvr47017.log shardsvr=true replset=myshardone 其中:shardsvr=true,表示这是一台分片服务器。
(6)创建第二个分片服务器的配置信息文件/data/47018/mongo_shardsvr_47018.conf
dbpath=/data/47018 port=47018 fork=true logpath=/data/47018/shardsvr47018.log shardsvr=true replset=myshardtwo
(7)启动所有的mongodb实例。
mongod --config /data/37017/mongo_configsvr_37017.conf mongod --config /data/37018/mongo_configsvr_37018.conf mongod --config /data/47017/mongo_shardsvr_47017.conf mongod --config /data/47018/mongo_shardsvr_47018.conf
(8)启动前端路由服务器
mongos --config /data/27017/mongos.conf
(9)使用mongoshell连接37017端口上的mongodb实例完成配置服务器复制集的初始化。
mongo --port 37017
(10)将37017和37018端口上的mongodb实例加入复制集中。
> cfg = {"_id":"myshardingconfig",
"members":[{"_id":0,"host":"127.0.0.1:37017"},
{"_id":1,"host":"127.0.0.1:37018"}]}
> rs.initiate(cfg)(11)查看复制集myshardingconfig的状态信息。
> rs.status()
# 输出的信息如下:
......
"members" : [
{
"_id" : 0,
"name" : "127.0.0.1:37017",
"health" : 1,
"state" : 1,
"statestr" : "primary",
......
},
{
"_id" : 1,
"name" : "127.0.0.1:37018",
"health" : 1,
"state" : 2,
"statestr" : "secondary",
......
}
],
......(12)使用mongoshell连接前端路由服务器。
mongo
(13)查看mongodb分片服务器的信息。
> sh.status()
# 输出的信息如下:
--- sharding status ---
sharding version: {
"_id" : 1,
"mincompatibleversion" : 5,
"currentversion" : 6,
"clusterid" : objectid("624d60d6675d42fb9b900362")
}
shards: --> 此处还没有添加任何的分片服务器地址信息。
active mongoses:
autosplit:
currently enabled: yes
balancer:
currently enabled: yes
currently running: no
failed balancer rounds in last 5 attempts: 0
migration results for the last 24 hours:
no recent migrations
databases:
{ "_id" : "config", "primary" : "config","partitioned" :true}(14)初始化47017上的复制集。
> cfg = {"_id":"myshardone",
"members":[{"_id":0,"host":"127.0.0.1:47017"}]}
> rs.initiate(cfg)(15)初始化47018上的复制集。
> cfg = {"_id":"myshardtwo",
"members":[{"_id":0,"host":"127.0.0.1:47018"}]}
> rs.initiate(cfg)(16)添加分片服务器
> sh.addshard("myshardone/127.0.0.1:47017")
> sh.addshard("myshardtwo/127.0.0.1:47018")(17)重新查看mongodb分片的信息。
> sh.status()
# 输出的信息如下:
--- sharding status ---
sharding version: {
"_id" : 1,
"mincompatibleversion" : 5,
"currentversion" : 6,
"clusterid" : objectid("624d60d6675d42fb9b900362")
}
shards: --> 分片中的服务器地址。
{"_id":"myshardone","host":"myshardone/127.0.0.1:47017",
"state":1,"topologytime":timestamp(1649238845,3)}
{"_id":"myshardtwo","host":"myshardtwo/127.0.0.1:47018",
"state":1,"topologytime":timestamp(1649238865,3)}
active mongoses:
"5.0.6" : 1
autosplit:
currently enabled: yes
balancer:
currently enabled: yes
currently running: no
failed balancer rounds in last 5 attempts: 0
migration results for the last 24 hours:
no recent migrations
databases:
{"_id":"config","primary":"config","partitioned" : true }(18)添加一个分片数据库。
> sh.enablesharding("mysharddb")(19)查看分片数据库的信息。
> sh.status()
# 输出的信息如下:
......
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
myshardone 992
myshardtwo 32
too many chunks to print, use verbose if you want to force print
{ "_id" : "mysharddb", "primary" : "myshardtwo",
"partitioned" : true,
"version":{"uuid": uuid("4c640f1f-77fe-45a6-92b4-b7c90692b845"),
"timestamp" : timestamp(1649239126, 36),
"lastmod" : 1 } }(20)修改数据分片的大小。
> use config
> db.settings.save( { _id:"chunksize", value:1})
注意:默认情况下,分片大小(chunk size)是64m。只有达到了分片的大小,才会进行分片。(21)开启集合上数据的分片。
> sh.shardcollection("mysharddb.table1",{"_id":1})
提示:这里使用了插入文档的_id作为片键来实现文档的分布式存储。(22)在数据库mysharddb中创建集合,并插入10万条文档
> use mysharddb
> for(var i = 1; i <= 100000; i++)
{db.table1.insert({"_id":i,"action":"write","iteration no:":i});}(23)再次查看分片数据库的信息。
> sh.status()
# 输出的信息如下:
......
mysharddb.table1
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
myshardone 6
myshardtwo 1
{"_id":{"$minkey":1}}-->>{"_id":2} on:myshardone timestamp(2,0)
{"_id": 2}-->>{"_id":20241} on:myshardtwo timestamp(3,1)
{"_id":20241}-->>{"_id":37933} on:myshardone timestamp(3,2)
{"_id":37933}-->>{"_id":55627} on:myshardone timestamp(3,4)
{"_id":55627}-->>{"_id":74150} on:myshardone timestamp(3,6)
{"_id":74150}-->>{"_id":91829} on:myshardone timestamp(3,8)
{"_id":91829}-->>{"_id":{"$maxkey":1}}on:myshardonetimestamp(3,9)
......从输出的信息可以看出,id值在{2,20241}的数据存储在了myshardtwo 的复制集上;而其他id值对应的数据存储在了myshardone的复制集上。因此可以得出结论,数据实现了分布式存储但效果不是很好。为了实现更好的数据分布式存储应当合理地选择片键。
到此这篇关于mongodb的分布式存储架构的文章就介绍到这了,更多相关mongodb分布式存储内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论