在数据分析的广阔领域中,数据透视表无疑是处理和理解海量数据的强大工具。它能够以灵活多变的方式汇总、分析数据,帮助我们从不同维度洞察数据背后的趋势和模式。然而,手动创建和更新数据透视表往往耗时耗力,尤其是在面对频繁更新的数据源或需要生成大量报告时,这种重复性工作会极大降低效率。
幸运的是,python作为数据科学领域的利器,为我们提供了自动化创建excel数据透视表的解决方案。本文将深入探讨如何利用python库,实现excel数据透视表的自动化生成、配置与格式化,从而显著提升您的数据处理和报表生成效率。我们将聚焦于一个功能强大且易于使用的库,它能完美模拟excel的数据透视表功能,让您摆脱繁琐的手工操作。
python环境配置与数据准备
要开始我们的自动化之旅,首先需要确保python环境已正确配置,并安装所需的库。本文将使用的核心库可以通过pip轻松安装:
pip install spire.xls
安装完成后,我们需要一些示例数据来演示如何创建数据透视表。以下python代码片段展示了如何使用该库向excel工作表写入一些模拟销售数据。这些数据包含了产品、区域、销售员和销售额等信息,足以支撑后续的数据透视表创建。
from spire.xls import *
# 创建一个新的工作簿
workbook = workbook()
# 清除默认工作表
workbook.worksheets.clear()
# 添加一个工作表
sheet = workbook.worksheets.add("销售数据")
# 写入标题行
sheet.range["a1"].value = "产品"
sheet.range["b1"].value = "区域"
sheet.range["c1"].value = "销售员"
sheet.range["d1"].value = "销售额"
sheet.range["e1"].value = "日期"
# 写入示例数据
data = [
["a", "华东", "张三", 1200, "2023-01-01"],
["b", "华南", "李四", 800, "2023-01-01"],
["a", "华东", "王五", 1500, "2023-01-02"],
["c", "华北", "张三", 2000, "2023-01-02"],
["b", "华南", "李四", 950, "2023-01-03"],
["a", "华西", "王五", 1100, "2023-01-03"],
["c", "华北", "赵六", 1800, "2023-01-04"],
["b", "华东", "张三", 700, "2023-01-04"],
["a", "华南", "李四", 1300, "2023-01-05"],
["c", "华西", "王五", 2200, "2023-01-05"]
]
for r_idx, row_data in enumerate(data):
for c_idx, cell_value in enumerate(row_data):
sheet.range[r_idx + 2, c_idx + 1].value = str(cell_value) # 从第二行开始写入数据
# 自动调整列宽
sheet.allocatedrange.autofitcolumns()
# 保存工作簿到文件
workbook.savetofile("salesdata.xlsx", excelversion.version2013)
print("示例数据已成功写入 salesdata.xlsx")
输出结果:
数据结构清晰是创建有效数据透视表的前提。在上述示例中,我们创建了一个包含“产品”、“区域”、“销售员”、“销售额”和“日期”等字段的表格,可后续的透视分析。
自动化创建数据透视表的核心步骤
现在我们有了数据,是时候利用python来创建数据透视表了。以下代码将演示如何指定数据源范围、透视表位置,并设置行字段、列字段、值字段和筛选字段。
# 加载之前保存的工作簿
workbook = workbook()
workbook.loadfromfile("salesdata.xlsx")
sheet = workbook.worksheets[0]
# 添加一个新的工作表用于存放数据透视表
pv_sheet = workbook.worksheets.add("销售数据透视表")
# 定义数据源范围
datarange = sheet.range["a1:e11"] # 包含标题行和所有数据
# 创建数据透视表缓存
cache = workbook.pivotcaches.add(datarange)
# 在新工作表的a1单元格创建数据透视表
# 参数:透视表名称, 目标位置, 缓存
pivottable = pv_sheet.pivottables.add("销售分析", pv_sheet.range["a1"], cache)
# 设置行字段 (row fields)
# 将“区域”和“销售员”作为行字段
rowfield_region = pivottable.pivotfields["区域"]
rowfield_region.axis = axistypes.row # 设置为行字段
rowfield_salesperson = pivottable.pivotfields["销售员"]
rowfield_salesperson.axis = axistypes.row # 设置为行字段
# 设置列字段 (column fields)
# 将“产品”作为列字段
colfield_product = pivottable.pivotfields["产品"]
colfield_product.axis = axistypes.column # 设置为列字段
# 设置值字段 (value fields)
# 将“销售额”作为值字段,并设置为求和
valuefield_sales = pivottable.pivotfields["销售额"]
# add方法用于添加值字段,参数1: 字段, 参数2: 自定义名称, 参数3: 汇总方式
pivottable.datafields.add(valuefield_sales, "总销售额", subtotaltypes.sum)
# 您也可以添加其他汇总方式,例如计数或平均值
# pivottable.datafields.add(pivottable.pivotfields["销售额"], "销售笔数", subtotaltypes.count)
# pivottable.datafields.add(pivottable.pivotfields["销售额"], "平均销售额", subtotaltypes.average)
# 设置筛选字段 (filter fields)
# 将“日期”作为筛选字段
reportfilter = pivotreportfilter("日期", true)
pivottable.reportfilters.add(reportfilter)
# 刷新数据透视表
pivottable.calculatedata()
# 保存工作簿
workbook.savetofile("salespivottable.xlsx", excelversion.version2016)
print("数据透视表已成功创建并保存到 salespivottable.xlsx")
输出结果:
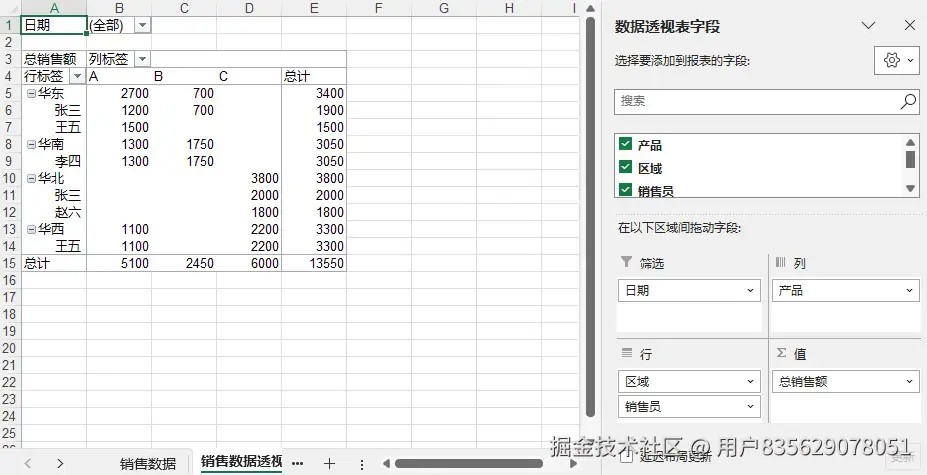
在上述代码中,我们首先加载了包含原始数据的工作簿,然后创建了一个新的工作表来放置数据透视表。关键在于pivottables.add()方法,它负责初始化透视表。接着,我们通过设置axis属性来指定每个字段的角色(行、列、值或筛选)。对于值字段,datafields.add()方法允许我们定义汇总方式,如subtotaltypes.sum(求和)。
优化数据透视表:布局与格式化
一个功能完善的数据透视表不仅需要准确地汇总数据,还需要具有良好的可读性和专业的外观。spire.xls for python提供了丰富的选项来调整数据透视表的布局和格式。
# 继续在之前创建的数据透视表上进行操作
workbook = workbook()
workbook.loadfromfile("salespivottable.xlsx")
pv_sheet = workbook.worksheets["销售数据透视表"]
pivottable = pv_sheet.pivottables[0] # 获取第一个数据透视表
# 1. 调整报表布局
# 设置为表格形式(table form),更清晰地展示数据
pivottable.options.rowlayout = pivottablelayouttype.tabular
# 启用重复项目标签,让每个行字段的值都显示
for field in pivottable.rowfields:
field.repeatitemlabels = true
# 2. 对值字段进行数字格式化
# 获取“总销售额”字段
valuefield = pivottable.datafields[0] # 假设“总销售额”是第一个值字段
# 设置为货币格式,带两位小数
valuefield.numberformat = "¥#,##0.00"
# 3. 设置数据透视表的样式和主题
# 应用内置样式,例如 pivotstylemedium12
pivottable.builtinstyle = pivotbuiltinstyles.pivotstylemedium12
# 也可以尝试其他样式,如 pivotstylelight10, pivotstyledark5等
# 4. 调整其他选项 (可选)
# 显示总计行
pivottable.rowgrand = true
# 显示总计列
pivottable.columngrand = true
# 自动调整列宽
pivottable.autoformatoption = autoformatoptions.all
# 刷新并保存工作簿
pivottable.calculatedata()
# 保存工作簿
workbook.savetofile("salespivottable_formatted.xlsx", excelversion.version2016)
print("数据透视表已成功格式化并保存到 salespivottable_formatted.xlsx")
输出结果:
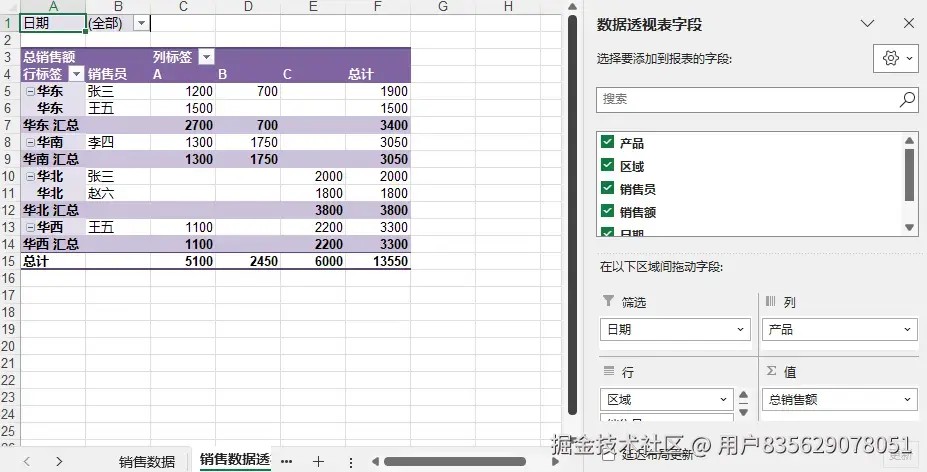
在这部分代码中,我们首先通过pivottable.options.rowlayout将报表布局设置为tabular(表格形式),并使用field.repeatitemlabels = true来重复显示行字段标签,这在多层行字段时能提高可读性。接着,我们对值字段应用了货币格式,使其更符合财务报表的要求。最后,通过pivottable.builtinstyle应用了excel内置的专业样式,让整个报表看起来更加美观。这些高级设置使得生成的报表不仅仅是数据的堆砌,更是专业分析的体现。
结语
通过本文的详细讲解和代码示例,您应该已经掌握了如何使用python库自动化创建和格式化excel数据透视表。从数据写入到透视表的复杂配置,python都能够提供高效且灵活的解决方案。这不仅能够将您从繁琐的重复性工作中解放出来,更能确保报表生成的一致性和准确性,极大地提升数据分析的效率和质量。
现在,是时候将这些技能应用到您的实际工作中了!尝试在您自己的数据集上自动化生成报表,探索不同的字段组合和汇总方式,您会发现python在数据自动化领域的无限潜力。随着您对该库的深入使用,您将能够构建出更加复杂和动态的数据透视报表,为您的数据分析工作带来革命性的改变。
到此这篇关于python自动化操作excel生成专业数据透视表的实战指南的文章就介绍到这了,更多相关python excel数据透视表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论