你可以使用 playwright 来获取当前页面的截图。以下是一个示例代码:
import os
import sys
from playwright.sync_api import sync_playwright
def find_chrome_executable():
"""
自动检测 chrome / chromium 在 windows / macos / linux 平台的常见安装位置。
找不到返回 none。
"""
if sys.platform.startswith("win"):
paths = [
os.path.expandvars(r"%programfiles(x86)%\google\chrome\application\chrome.exe"),
os.path.expandvars(r"%programfiles%\google\chrome\application\chrome.exe"),
os.path.expandvars(r"%localappdata%\google\chrome\application\chrome.exe"),
]
elif sys.platform.startswith("darwin"): # macos
paths = [
"/applications/google chrome.app/contents/macos/google chrome",
"/applications/chromium.app/contents/macos/chromium",
]
elif sys.platform.startswith("linux"):
paths = [
"/usr/bin/google-chrome",
"/usr/bin/google-chrome-stable",
"/usr/bin/chromium",
"/usr/bin/chromium-browser",
"/snap/bin/chromium",
]
else:
return none
for path in paths:
if os.path.exists(path):
return path
return none
def click_first_link_in_hotsearch_and_get_url():
chrome_path = find_chrome_executable()
if not chrome_path:
print("❌ 未找到本地 chrome,程序退出。")
return
print(f"✔ 使用本地 chrome:{chrome_path}")
with sync_playwright() as p:
# 不允许 fallback 用内置 chromium
browser = p.chromium.launch(executable_path=chrome_path, headless=true)
page = browser.new_page()
page.goto('https://www.baidu.com')
page.wait_for_load_state('load')
hotsearch_selector = '#s-hotsearch-wrapper'
page.wait_for_selector(hotsearch_selector)
hotsearch_element = page.query_selector(hotsearch_selector)
if hotsearch_element:
first_link = hotsearch_element.query_selector("a")
if first_link:
url = first_link.get_attribute('href')
print(f"第一个链接url:{url}")
page.goto(url)
page.wait_for_load_state('load')
screenshot_path = 'screenshot_after_click.png'
page.screenshot(path=screenshot_path)
print(f"截图已保存到 {screenshot_path}")
else:
print("热搜区未找到链接")
else:
print("页面上未找到热搜元素")
browser.close()
if __name__ == '__main__':
click_first_link_in_hotsearch_and_get_url()
在这个示例中,page.screenshot() 方法用于获取当前页面的截图,并将其保存到指定的文件路径(screenshot.png)。确保替换 ‘https://www.baidu.com’ 为你想要截图的实际网址。如果你希望在截图后不关闭浏览器,记得注释掉 browser.close() 部分。
注意:截图之前最好等待页面加载完成,以确保获取到完整的页面截图。在这个示例中,使用了 page.wait_for_load_state(‘load’) 来等待页面加载完成,但你可能需要根据实际情况调整等待的条件。
知识扩展
下面我们来看看如何利用playwright库在python中进行屏幕截图、截取全页面长图以及特定元素的截图。
捕获屏幕截图保存
page.screenshot(path="screenshot.png")
代码如下(示例):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=false, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("https://blog.csdn.net/weixin_44688529?spm=1010.2135.3001.5343")
print(page.title())
page.screenshot(path="screenshot.png")
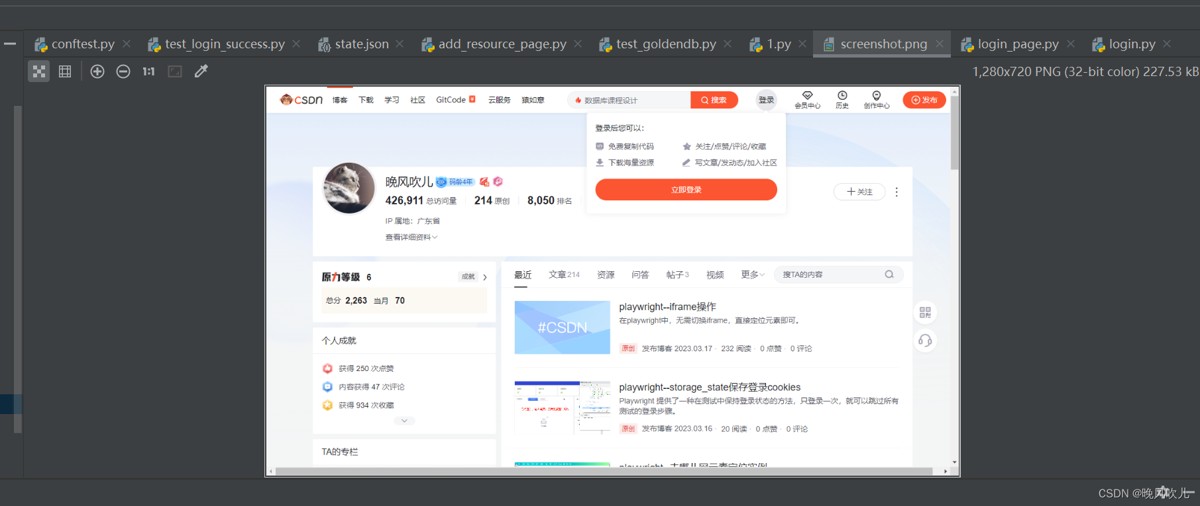
截长图
page.screenshot(path="screenshot.png", full_page=true)
代码如下(示例):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=false, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("https://blog.csdn.net/weixin_44688529?spm=1010.2135.3001.5343")
print(page.title())
page.screenshot(path="screenshot.png", full_page=true)
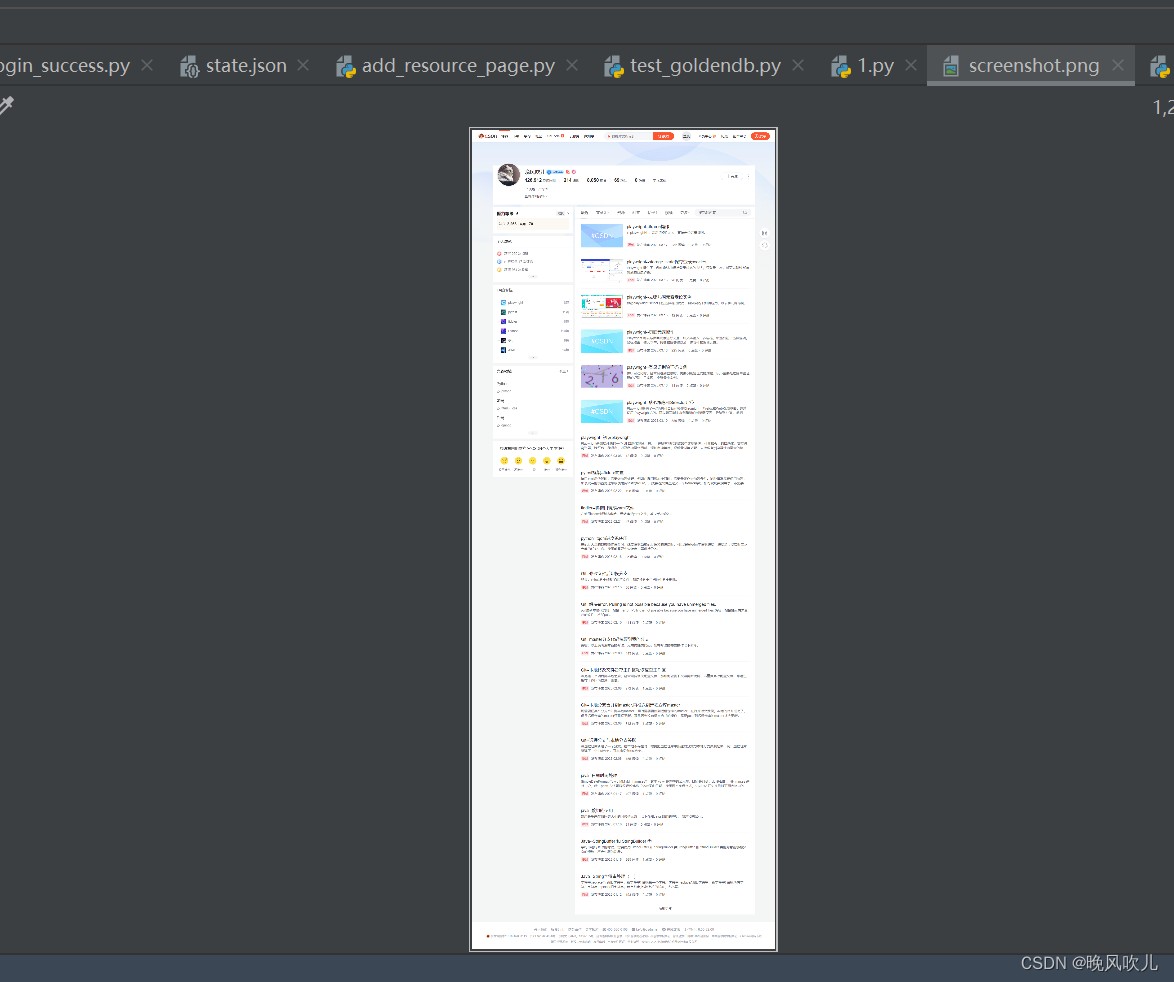
截取单个元素
先定位到需要截图的元素,再截图保存
from playwright.async_api import playwright
from playwright.sync_api import sync_playwright
def run(playwright: playwright):
# 启动 chromium 浏览器
browser = p.chromium.launch(headless=false,slow_mo=1000)
context = browser.new_context()
# 打开一个标签页
page = context.new_page()
# 打开百度
page.goto("http://192.168.64.209:8008/#/login")
# 打印当前页面title
print(page.title())
page.locator(".s-canvas").screenshot(path="example.png")

到此这篇关于python playwright实现获取当前页面的截图的文章就介绍到这了,更多相关 playwright获取截图内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论