对于要搭建一套电脑玩本地ai主机的朋友来讲,显卡的显存容量决定了可以加载的ai模型体积。但目前来看,12gb以上显存的主流独显基本上都要几千元,那么有没有一种性价比更高的解决方案,可以同时满足高效和支持较大ai模型的需求呢?
实际上,我们在完成一些精度不太高的aigc任务时,可以适当降低对模型参数的要求,从而让显存较小的独显也能高效处理;而在需要大体积ai模型来完成高精度aigc任务时,改用可以手动分配大显存的集显来应对。像是radeon 780m这类集显,就支持最高手动分配16gb显存,成本远低于16gb显存的高性能独显,因此性价比方面非常突出。

那么,接下来我们就用技嘉b850m aorus pro wifi7电竞雕(以下简称b850m电竞雕)主板搭配锐龙7 8700g(内置radeon 780m集显)+ 64gb内存+ rtx 5060独显来实战测试一下,看看这个解决方案是否能满足需求。
集显配独显更灵活,满足本地不同模型ai加速需求
测试平台介绍
- 主板:技嘉b850m aorus pro wifi7电竞雕
- 处理器:锐龙7 8700g
- 内存:kingston fury renegade ddr5 6400 32gb×2
- 显卡:技嘉rtx 5060魔鹰
- 硬盘:希捷酷玩540 2tb
- 电源:技嘉魔鹰1000pg5
- 操作系统:windows 11专业版24h2
锐龙7 8700g处理器

锐龙7 8700g作为am5平台中的apu旗舰,拥有桌面平台最强的集显gpu:radeon 780m。同时,由于它的集显支持手动分配超大容量的内存来当显存使用,使得它可以在加载本地大体积ai模型时避免“爆显存”。例如在系统拥有32gb甚至更大容量内存时,它就可以分配最多16gb内存作为显存,而独立显卡即便是4000多元的rtx 5070,也只有12gb显存,主流2000元级的rtx 5060更是只有8gb显存,在加载超过这个容量的本地ai模型时就会爆显存,出现计算效率暴降的问题。而锐龙7 8700g的集显在模型体积低于16gb时都不会爆显存,计算效率明显高于cpu和“爆显存”状态的独显。因此,如果用户有加载超过8gb本地ai模型的需求,1800元出头的锐龙7 8700g甚至比几千元的独显更有实用价值。
技嘉b850m aorus pro wifi7电竞雕
主板搭载了12(sps 80a)+2(sps 80a)+2相供电设计,并配备了epic vrm散热器,提供了4倍散热面积,同时还配备了高效导热垫,在一体化i/o背板上也设计了通风孔矩阵,因此可以大幅降低vrm电路的工作温度,让vrm电路在搭载锐龙旗舰处理器满血输出时也能保持更低的温度。
内存部分,主板提供了4条内存插槽,最高支持ddr5 8600(oc)高频内存,并且还支持全新的ai d5黑科技2.0技术,不但具备经典的内存高带宽功能,还可以通过ai snatch工具实现一键超内存,让普通玩家也能轻松享受免费的内存性能提升。
扩展部分,主板提供了两条全长pcie插槽,其中第一条支持pcie 5.0×16,一条支持pcie 4.0×4,对于matx主机来讲完全够用。此外,第一条pcie插槽还加装了合金装甲,提供更好的物理防护能力和抗干扰能力,而且还支持快易拆,按下按键即可轻松拆卸显卡。
m.2插槽部分,主板提供了两个pcie 5.0×4,第一条最高支持25110规格,第二条最高支持22110规格,两个插槽配备了一体式全覆盖散热装甲,并支持快易拆,拆装ssd和散热装甲都完全不需要工具。
接口部分,主板的一体式i/o面板上提供了一个usb-c 3.2 gen2、两个usb-a 3.2 gen2、四个usb-a 3.2 gen1和4个usb-a 2.0/1.1接口,同时还有wifi 7无线网卡和2.5gbps有线网卡,无线网卡搭配了磁吸天线,安装起来也很方便。此外,经典的q-flash按键它也是具备的。
kingston fury renegade ddr5 6400 32gb×2套装

金士顿的fury renegade系列ddr5内存在玩家中一直保持不错的口碑,这一系列最高有总容量96gb的双条套装,频率最高可支持到ddr5 8800规格。我们本次测试使用的是dd5 6400 32gb×2(时序为cl32-39-39-80)的套装,对于有ai应用需求的玩家来讲,更大的内存无疑可以提供更大的模型支持,同时也能保证系统有足够多的剩余内存来加载更多的进程、提供流畅的操控体验。fury renegade系列还搭载了高效的铝质散热器,让内存在高负载工作状态下也能保持凉爽的温度,从而保证其稳定性和耐用度。
测试设置
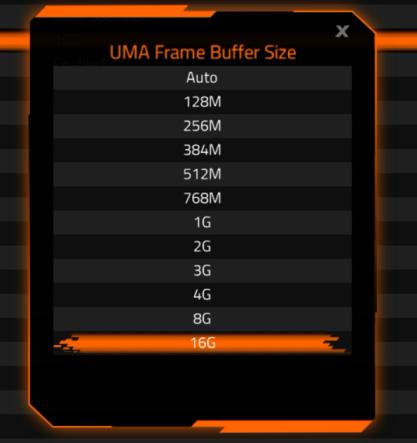
▲在技嘉b850m电竞雕bios中为锐龙7 8700g内置的radeon 780m集显手动分配16gb显存
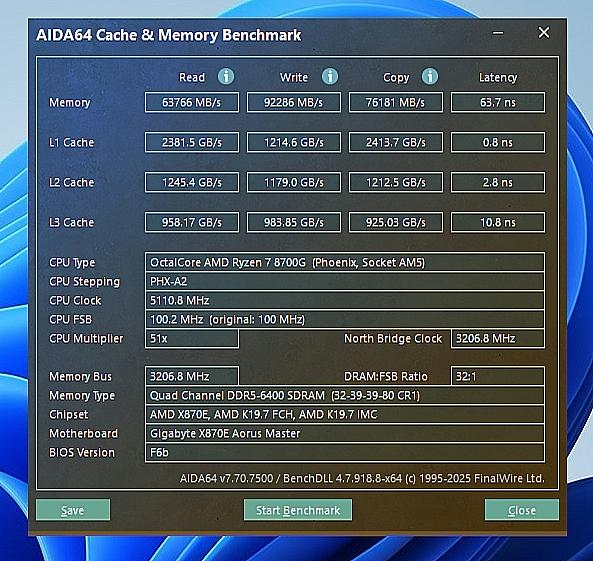
▲技嘉b850m电竞雕可以很好地支持ddr5 6400 32gb×2套条
我们用技嘉b850m电竞雕主板来搭配ddr5 6400 32gb×2内存套装,从而使锐龙7 8700g可以手动分配到最高16gb内存作为专属显存使用。从aida64测试可以看到,技嘉b850m电竞雕主板搭配ddr5 6400 32gb×2发挥出了应有的性能,在cl=32的设置下,延迟也压到了63.7ns,表现非常不错,出色的内存性能对于提升集显性能很有帮助。
lmstudio测试
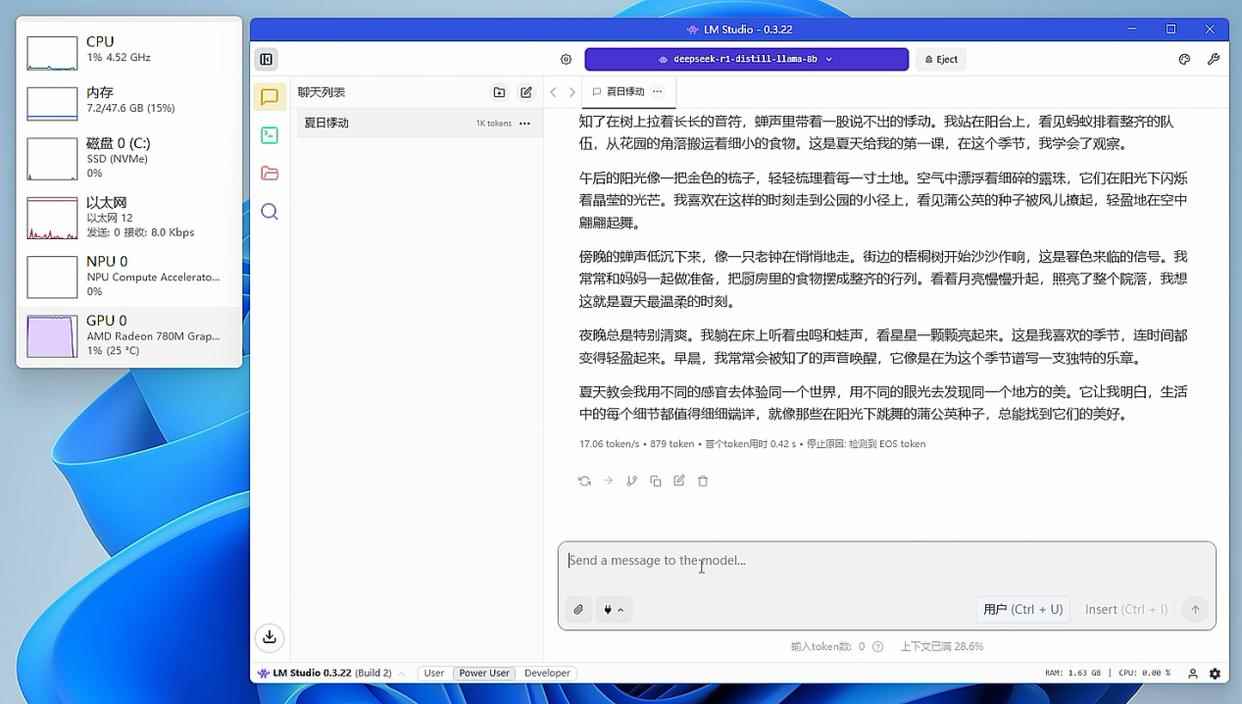
▲加载8b模型时,radeon 780m的处理速度为17.06 token/s
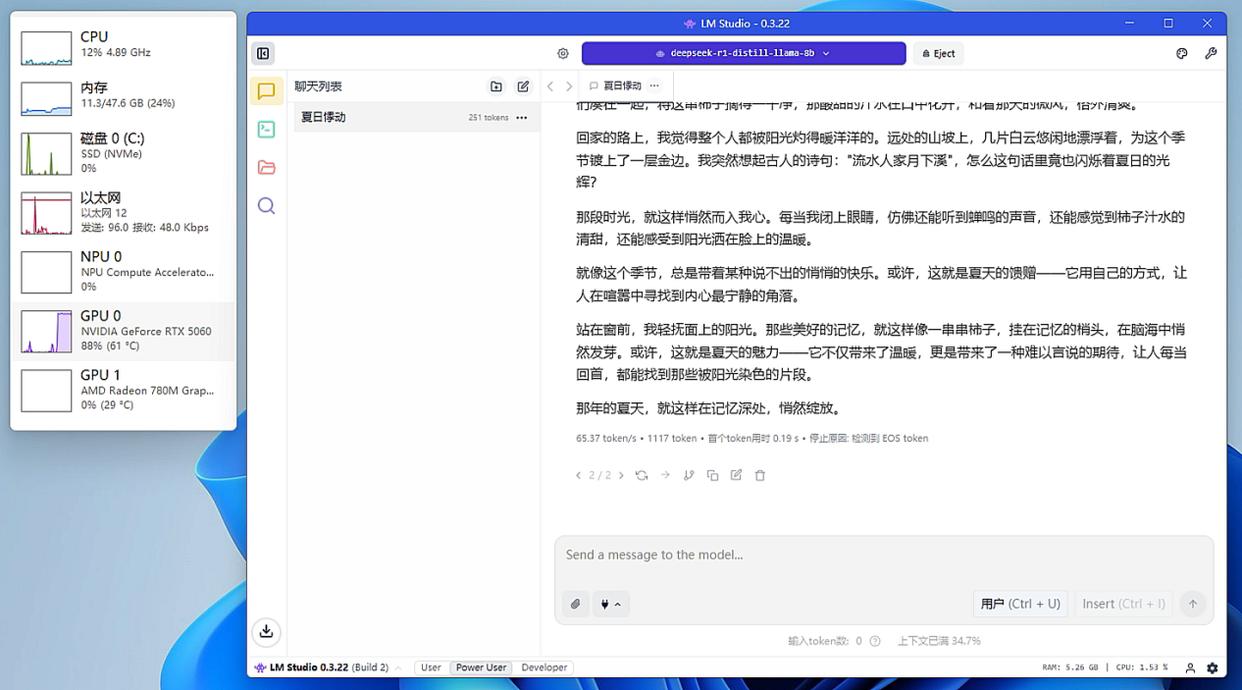
▲加载8b模型时,rtx 5060的处理速度为65.37 token/s
我们使用lmstudio加载deepseek-r1-distill-llama-8b模型(占用4.58gb显存)来完成写一篇800字作文,radeon 780m的处理速度为17.06 token/s,rtx 5060的处理速度为65.37 token/s。毕竟这个模型只占用4.58gb显存,而在没有“爆显存”的前提下,rtx 5060相对radeon 780m的处理速度确实是要快出几倍的。接下来我们看看“爆显存”之后会怎样。
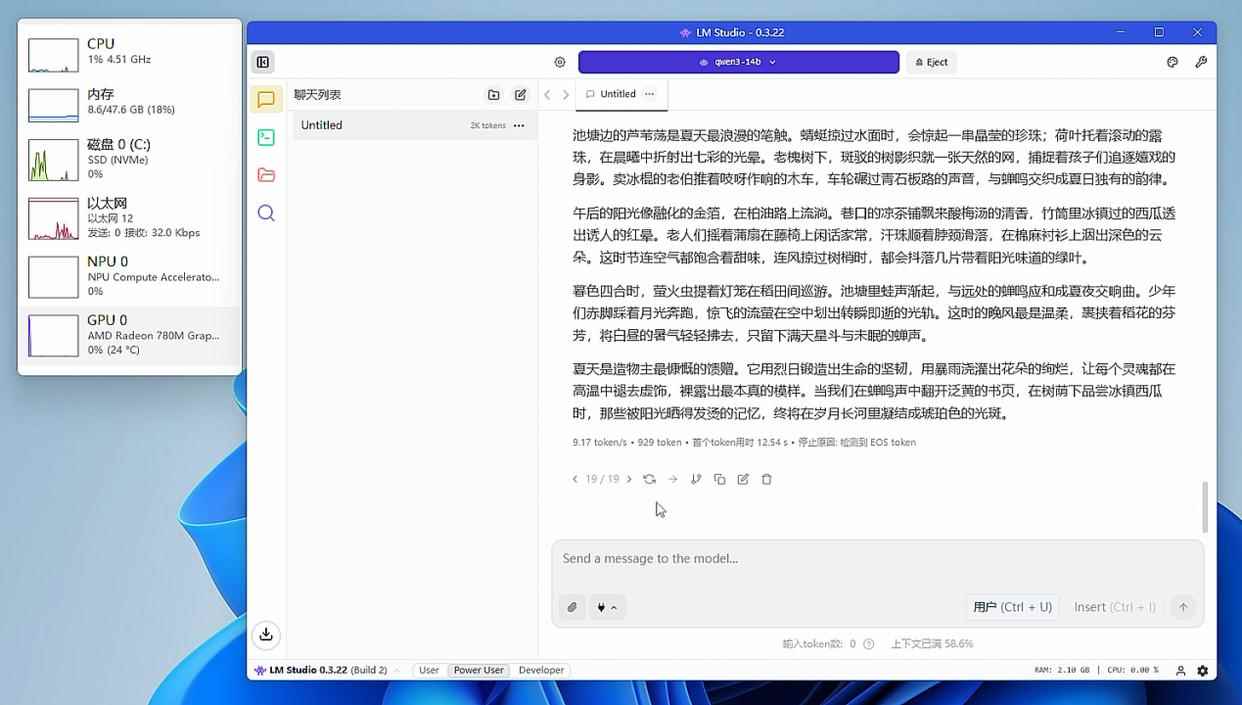
▲加载14b模型时,radeon 780m的处理速度为9.17 token/s
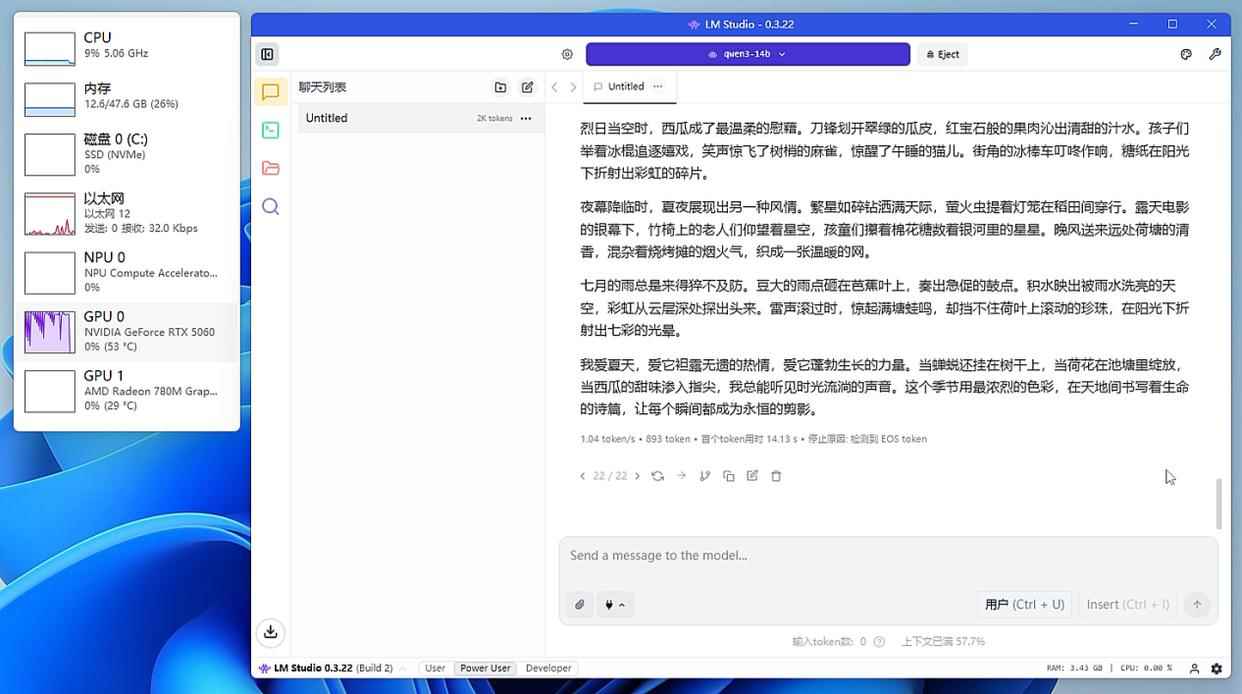
▲加载14b模型时,rtx 5060的处理速度为1.04 token/s
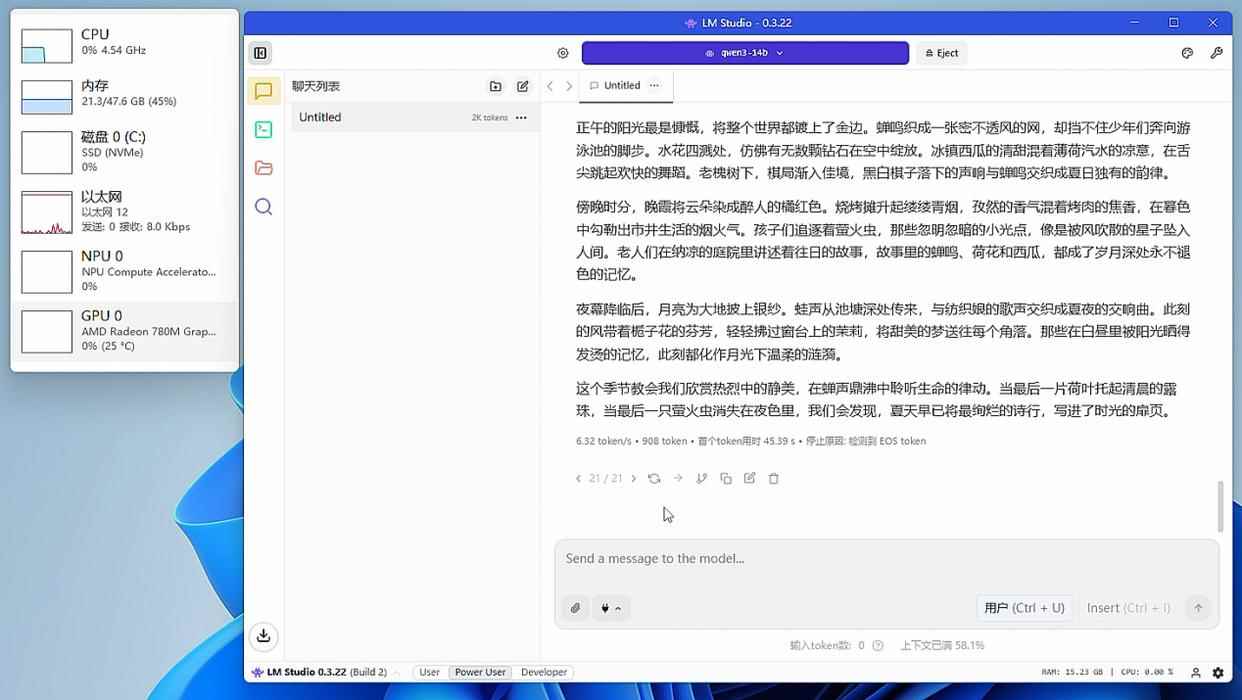
▲加载14b模型时,锐龙7 8700g通过cpu处理的速度为6.32 token/s
如果我们把模型换成qwen3 14b(占用8.38gb显存),它的体积已经超过了rtx 5060 8gb显存的上限,所以此时rtx 5060处于“爆显存”状态,而radeon 780m拥有手动分配的16gb显存,自然没“爆显存”。可以看到,此时radeon 780m处理速度为9.17 token/s,而rtx 5060处理速度只有1.04 token/s了,甚至还不如锐龙7 8700g纯cpu处理快。由此可见,得益于海量的显存设置,radeon 780m这类集显就可以在加载大体积模型的时候避免“爆显存”,从而获得远超“爆显存”高性能独显的处理速度。
总结:集显+独显取长补短,搭建高性价比全能ai平台
最后来简单总结一下。从前面的测试结果我们可以观察到,在没“爆显存”时,高性能独显相对集显的ai处理速度确实要快出很多,但在“爆显存”情况下,就远不及没爆显存的“大显存”集显了。因此,如果用“锐龙7 8700g + 大内存 + 高性能独立显卡”这个组合,然后手动给集显分配超大显存,就既能保证加载较小ai模型时的处理速度(使用rtx 5060处理),也能保证面对较大ai模型时不会“爆显存”导致效率大降(使用radeon 780m处理),从而提供更好的ai应用适应性。例如我们选择的锐龙7 8700g + 技嘉b850m电竞雕 + 技嘉rtx 5060魔鹰,就是一个性价比和可靠性都非常优秀的全能ai解决方案。

发表评论