一、性能检测(监控)
1. cpu1. cpu 监控
命令 | 功能 | 关键参数/输出 | 场景 |
|---|---|---|---|
top / htop | 实时进程级 | %cpu(进程占用率)、%mem(内存占用率)、load average(负载平均值) | 快速定位高 cpu 进 |
mpstat -p all 1 | 每个核心的 cpu 使用率 | %usr(用户态)、%sys(内核态)、%iowait(i/o 等待) | 多核负载均衡分析 |
uptime | 系统负载与运行时间 | 11:32:20 up 3:21, 2 users, load average: 0.00, 0.01, 0.05 | 快速查看负载趋势 |
perf top | 实时 cpu 热点函数分析 | 按函数名排序 cpu 占用率 | 深入代码级 |
说明:
1.top
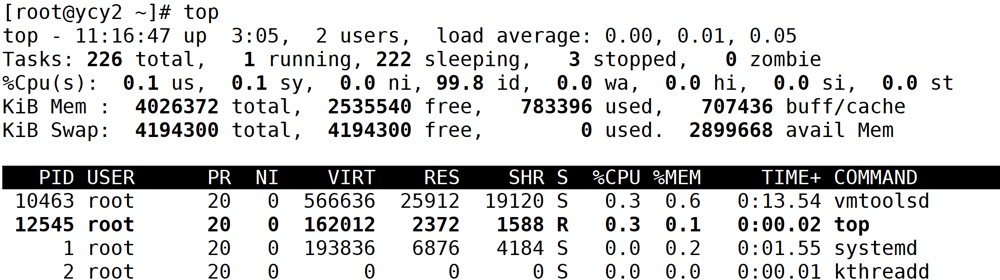
| 分类 | 具体指标 | 数值 / 说明 |
|---|---|---|
| 系统基本信息 | 当前时间 | 11:16:47 |
| 开机时长 | up 3:05(已开机 3 小时 05 分钟) | |
| 登录用户数 | 2 users | |
| 系统平均负载 | load average: 0.00, 0.01, 0.05(1 分钟、5 分钟、15 分钟平均负载) | |
| 任务(进程)统计 | 总进程数 | 226 total |
| 运行中进程数 | 1 running | |
| 休眠进程数 | 222 sleeping | |
| 停止进程数 | 3 stopped | |
| 僵尸进程数 | 0 zombie | |
| cpu 使用率 | 用户态(us) | 0.1%(应用程序占用 cpu 比例) |
| 内核态(sy) | 0.1%(系统内核功能占用 cpu 比例) | |
| 调整优先级的用户态(ni) | 0.0% | |
| 空闲(id) | 99.8%(空闲 cpu 比例,越高越空闲) | |
| 等待 i/o(wa) | 0.0%(因等待磁盘、网络等 i/o 操作占用 cpu 耗时比例) | |
| 硬件中断(hi) | 0.0%(处理硬件中断占用 cpu 耗时比例) | |
| 软件中断(si) | 0.0%(处理软件中断占用 cpu 耗时比例) | |
| 被虚拟机 “偷走”(st) | 0.0%(虚拟机场景下,被其他虚拟机占用的 cpu 时间比例) | |
| 内存信息 | 总物理内存(kib mem total) | 4026372 kib(约 4gb ) |
| 空闲物理内存(free) | 2535540 kib | |
| 已用物理内存(used) | 783396 kib | |
| 缓存(buff/cache) | 707436 kib(可被释放给应用的临时缓存) | |
| 交换分区信息 | 总交换分区(kib swap total) | 4194300 kib(约 4gb ) |
| 空闲交换分区(free) | 4194300 kib | |
| 已用交换分区(used) | 0 kib(未用到磁盘交换,性能较好) | |
| 实际可用内存(avail mem) | 2899668 kib(含可回收缓存,体现实际可用内存) | |
| 进程详情 | pid(进程 id) | 10463、12545、1、2 等 |
| user(所属用户) | root(所列进程均属 root 用户 ) | |
| pr(进程优先级) | 20(数值越小优先级越高,所列进程多为 20 ) | |
| ni(nice 值) | 0(调整进程优先级,范围 -20 ~ 19 ) | |
| virt(虚拟内存总量) | 如 566636 kib(vmtoolsd 进程)、162012 kib(top 进程 )等 | |
| res(实际物理内存占用) | 如 25912 kib(vmtoolsd 进程)、2372 kib(top 进程 )等 | |
| shr(共享内存) | 如 19120 kib(vmtoolsd 进程)、1588 kib(top 进程 )等 | |
| s(进程状态) | s(休眠)、r(运行,如 top 进程状态为 r )等 | |
| % cpu(进程 cpu 使用率) | 如 0.3%(vmtoolsd、top 进程 )、0.0%(systemd 等进程 ) | |
| % mem(进程内存使用率) | 如 0.6%(vmtoolsd 进程)、0.1%(top 进程 )、0.2%(systemd 进程 )等 | |
| time+(累计 cpu 耗时) | 如 0:13.54(vmtoolsd 进程)、0:00.02(top 进程 )、0:01.55(systemd 进程 )等 | |
| command(进程名称 / 命令) | vmtoolsd、top、systemd、kthreadd 等 |
2.mpstat -p all 1

| 列名 | 全称 / 含义 | 示例值(以 all 行为例) | 补充说明 |
|---|---|---|---|
| 11:27:17 am11:27:18 am | 采样时间 | 采样时间戳 | 第一行是 “表头时间”,后续是实际采样时间 |
| cpu | cpu 标识:- all = 所有 cpu 总览- 0/1 = 单个 cpu 核心编号 | all、0、1 | 你的输出里还有 2、3 核心(截图未完整显示) |
| %usr | 用户态 cpu 使用率(应用程序、脚本等用户空间程序占用 cpu 比例) | 0.00 | 数值越高,用户程序越繁忙 |
| %nice | 调整过优先级(nice 值)的用户态 cpu 使用率 | 0.00 | 通常为 0(少用优先级调整时) |
| %sys | 内核态 cpu 使用率(系统内核功能、驱动等占用 cpu 比例) | 0.25(all 行) | 数值高可能因内核任务多(如 i/o 调度) |
| %iowait | cpu 等待 i/o 耗时比例(因磁盘、网络等 i/o 阻塞,cpu 空闲等待的时间) | 0.00 | 高值可能表示存储 / 网络性能瓶颈 |
| %irq | 硬件中断(如键盘、磁盘控制器触发)占用 cpu 比例 | 0.00 | 通常较低,驱动异常时可能升高 |
| %soft | 软件中断(内核内部触发的中断)占用 cpu 比例 | 0.00 | 同上,异常时需关注 |
| %steal | 虚拟机场景下,被宿主机 “偷走” 的 cpu 时间(仅虚拟机内可见) | 0.00 | 物理机无此损耗,虚拟机需关注 |
| %guest | 运行虚拟机客户机(如 kvm 虚机)占用的 cpu 比例 | 0.00 | 无虚拟机时通常为 0 |
| %gnice | 调整过优先级的虚拟机客户机 cpu 使用率 | 0.00 | 同上,少用场景为 0 |
| %idle | cpu 空闲比例(完全无任务时的空闲时间) | 99.75(all 行) |
2. 内存监控
命令 | 功能 | 关键参数/输出 | 场景 |
|---|---|---|---|
free -h | 内存使用情况(人类可读) | available(可用内存)、buff/cache(缓存)、used(已用) | **关键指标:关键指标:available < 10% 需警惕 |
vmstat 1 5 | 内存、进程、i/o 综合统计 | si/so(swap 交换量)、bi/bo(磁盘r(运行队列长度 | 内存不足或 i/o 瓶颈 |
sar -r 1 5 | 内存使用率历史数据 | kbmemfree(空闲内存)、kbmemused(已用内存)、%memused(使用率) | 长 |
1.free -h
| 分类 | 字段 | 含义 & 示例值 | 补充说明 |
|---|---|---|---|
| 内存 | total | 总物理内存:3.8g | 系统总内存约 3.8gb |
| used | 已用内存:765m | 实际被程序占用的内存 | |
| free | 空闲内存:2.4g | 完全未被使用的 “纯空闲” 内存 | |
| buff/cache | 缓存内存:690m | 用于磁盘缓存(可释放给程序) | |
| available | 可用内存:2.8g | 程序实际可申请的内存(含可回收缓存) | |
| 交换分区 | total | 总交换空间:4.0g | 硬盘模拟的 “虚拟内存” 总大小 |
| used | 已用交换:0b | 未用到交换分区(性能好) | |
| free | 空闲交换:4.0g | 交换分区剩余空间 |
总结:系统物理内存充足(总 3.8g,已用仅 765m,可用 2.8g ),且未用到交换分区(swap 用 0b ),内存状态非常健康,无内存压力~
2.vmstat 1 5

3.sar -r 1 5

3. 磁盘 i/o 监控
命令 | 功能 | 关键参数/输出 | 场景 |
|---|---|---|---|
iostat -dx 1 5 | 磁盘 i/o 性能(扩展模式) | %util(设备繁忙度)、await(i/o 延迟)、r/s(读请求数)、w/s(写请求数) | 瓶颈判断:%util > 80% 或 await > 20ms |
df -h | 磁盘分区空间使用率 | use%(使用率)、mounted on(挂载点) | 磁盘空间告 |
1.iostat -dx 1 5
| 分类 | 字段 / 列名 | 含义 & 示例值 | 补充说明 |
|---|---|---|---|
| 磁盘设备 | device | 磁盘设备名:scd0、sda | sda 通常是主硬盘,scd0 可能是光驱 |
| i/o 指标 | tps | 每秒 i/o 操作数:scd0: 0.00sda: 0.44 | 数值越高,磁盘越繁忙 |
| kb_read/s | 每秒读数据量(kb):scd0: 0.02sda: 15.91 | 读吞吐量,反映读性能 | |
| kb_wrtn/s | 每秒写数据量(kb):scd0: 0.00sda: 1.25 | 写吞吐量,反映写性能 | |
| 累计统计 | kb_read | 累计读总量(kb):scd0: 1050sda: 676095 | 系统启动以来的读总数据量 |
| kb_wrtn | 累计写总量(kb):scd0: 0sda: 53193 | 系统启动以来的写总数据量 |
关键结论:
sda(主硬盘):有一定读写活动(tps=0.44、kb_read/s=15.91、kb_wrtn/s=1.25),但整体负载低,属于正常使用状态。scd0(可能是光驱):读写极少(tps=0.00、kb_wrtn/s=0.00),符合光驱低使用场景。系统磁盘 i/o 压力小,无明显性能瓶颈。
4. 网络监控
命令 | 功能 | 关键参数/输出 | 场景 |
|---|---|---|---|
sar -n dev 1 5 | 网络接口流量统计 | rxkb/s(接收速率)、txkb/s(发送速率)、rxerr/s(接收错误) | 带宽瓶颈或丢包问题 |
ss -tuln | 监听端口与连接状态 | listen(监听端口)、estab(已建立连接) | 检查服务端口是否正常 |
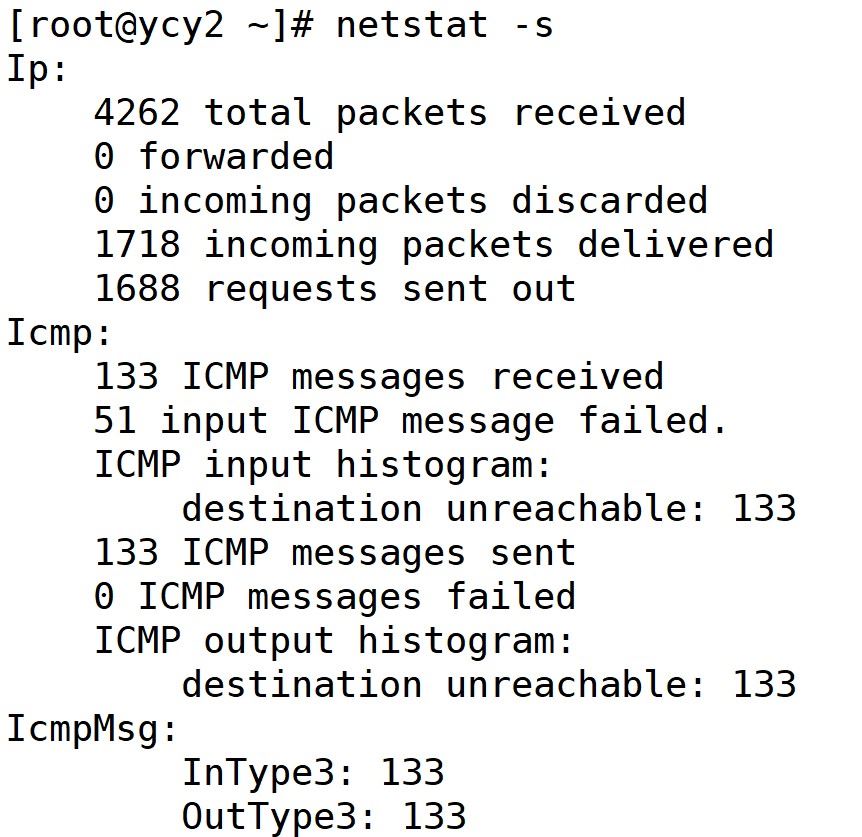
netstat -s | 网络协议统计(tcp/udp/icmp) | segments retransmitted(tcp 重传)、packet receive errors(接收错误) | 网络层问题分析 |
1.sar -n dev 1 5
2.ss -tuln

3.netstat -s
5. 综合监控工具
工具 | 功能 | 特点 |
|---|---|---|
dstat | cpu/内存/磁盘/网络一体化监控 | dstat -tcmndpy(时间+cpu+内存+磁盘+网络+系统调用) |
glances | 跨平台系统监控(web/终端) | 支持插件扩展,可监控 docker、传感器等 |
nmon | 实时性能监控 + 数据导出 | 生成 csv 报告用于长期分析 |
二、性能调优(优化)
1. cpu 调优
场景 | 调优策略 | 命令/配置 |
|---|---|---|
进程 cpu 绑定 | 减少跨 cpu 核心切换开销 | taskset -cp 0,1 <pid>(绑定进程到核心 0,1) |
中断亲和性 | 分散网卡中断到不同 cpu 核心 | echo 1 > /proc/irq/<中断号>/smp_affinity(绑定到 cpu 0) |
cpu 频率调节 | 固定高性能模式(省电场景用 ondemand) | cpupower frequency-set -g performance |
减少上下文切换 | 降低线程数或使用异步 i/o | 优化应用代码(如使用 nginx 的 worker_processes auto) |
2. 内存调优
场景 | 调优策略 | 命令/配置 |
|---|---|---|
减少 swap 使用 | 避免内存频繁交换到磁盘(需确保物理内存充足) | sysctl vm.swappiness=10(默认 60,0 表示禁用 swap) |
调整脏页回写 | 减少磁盘写频率,提升写性能 | sysctl vm.dirty_ratio=15(脏页占比达 15% 时阻塞写) |
启用大页内存 | 减少 tlb miss(适用于数据库、虚拟化) | echo 2048 > /proc/sys/vm/nr_hugepages(分配 2048 个 2mb 大页) |
oom killer 保护 | 防止关键进程被杀 | echo -1000 > /proc/<pid>/oom_score_adj(值越低越不易被杀) |
3. 磁盘 i/o 调优
场景 | 调优策略 | 命令/配置 |
|---|---|---|
更换 i/o 调度器 | ssd 用 none/mq-deadline,hdd 用 mq-deadline | echo mq-deadline > /sys/block/sda/queue/scheduler |
调整队列深度 | 提高并发 i/o 能力(ssd 可设 256-1024) | echo 512 > /sys/block/sda/queue/nr_requests |
启用读写预取 | 提升顺序读写性能 | echo 1024 > /sys/block/sda/queue/read_ahead_kb(单位 kb) |
文件系统挂载优化 | 禁用访问时间更新、启用写回模式 | mount -o noatime,nodiratime,data=writeback /dev/sda1 /mnt |
4. 网络调优
场景 | 调优策略 | 命令/配置 |
|---|---|---|
调整 tcp 缓冲区 | 高带宽或高延迟网络需增大缓冲区 | sysctl net.ipv4.tcp_rmem="4096 87380 16777216"(最小/默认/最大接收缓冲区) |
启用 bbr 拥塞算法 | 提升高丢包网络吞吐量(需内核 ≥4.9) | sysctl net.ipv4.tcp_congestion_control=bbr |
连接复用 | 减少 time_wait 连接 | sysctl net.ipv4.tcp_tw_reuse=1 |
增大连接跟踪表 | 高并发服务器(如 nat 网关) | sysctl net.netfilter.nf_conntrack_max=1000000 |
三、调优实战案例
场景:web 服务器响应缓慢
1.监控诊断
top # 发现 cpu 占用 90%,负载 15(8核机) vmstat 1 # 显示 r(运行队列)>10,so(swap out)>0 free -h # available 内存仅 500mb(总 16gb)
结论:cpu 瓶颈 + 内存不足导致 swap。
2.调优措施
2.1 应用层
# 优化 nginx 配置(减少 worker 数) worker_processes auto; worker_connections 512; # 原值 1024
# 优化慢 sql(如添加索引) explain select * from users where name='alice';
2.2 内核层
sysctl vm.swappiness=10 # 减少 swap sysctl net.ipv4.tcp_tw_reuse=1 # 复用 time_wait 连接
硬件:增加内存至 32gb。
3.验证效果
ab -n 10000 -c 100 http://localhost/ # 压力测试 # 结果:tps 从 200 提升至 800,响应时间从 500ms 降至 120ms
- 安全第一:生产环境调优前 务必备份,
- 单一变量:每次只修改一个参数,避免无法定位问题根源。 3
- 监控先行:调优后持续
sar -u 1 3600记录 1 小时 cpu)。 4
工具选择:
- 快速诊断:`
top/vmstat/iostat - 深度分析:
perf/ebpf(bcc-tools) - 长期
prometheus + grafana
五、命令速查表
目标 | 命令 | 输出关键字 |
|---|---|---|
cpu 瓶颈 | mpstat -p all 1 | %usr > 80% 或 %iowait > 20 |
内存不足 | free -h | available < 10% 总内存 |
磁盘瓶颈 | iostat -dx 1 | %util > 80% 或 `awaitawait > 20ms |
网络丢包 | sar -n dev 1 | rxerr/s > 0 或 rxdrop/s > 0 |
高负载进程 | ps aux --sort=-%cpu | head -10 | 第一列高 cpu 进 |
swap 使用 | vmstat 1 | si 或 so 持 |
六、linux内核版本优化
linux内核优化
- 升级内核
rpm -ivh kernel-3.10...rpm
- 查看内核模块
/lib/modules
- uname -r 查看内核版本
3.10.0-957.el7.x86_64
内核版本号由3部分组成
- 3.10.0-957
- 主版本号
- 次版本号:次版本号决定该内核是稳定版本还是开发版本 偶数稳定版本 奇数 开发版本
- 末版本号(修订版本号)
查询模块
lsmod |grep xfs modinfo xfs
- 加载模块
modprobe ext4
- 卸载模块
modprobe -r ext4
- 开启ip转发
vim /etc/sysctl.conf net.ipv4.ip_forward = 1 sysctl -p /etc/sysctl.conf
- 开启禁ping
vim /etc/sysctl.conf net.ipv4.icmp_echo_ignore_all = 1 sysctl -p /etc/sysctl.conf
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论