java中的redis bigkey问题解析
一、bigkey 定义与危害分析
1.1 核心定义
bigkey 是指 redis 中 value 体积异常大的 key,通常表现为:
- 字符串类型:value 超过 10kb
- 集合类型:元素数量超过 1 万(list/set)或 5 千(hash/zset)
- 流类型:stream 包含数万条消息
1.2 危害全景图
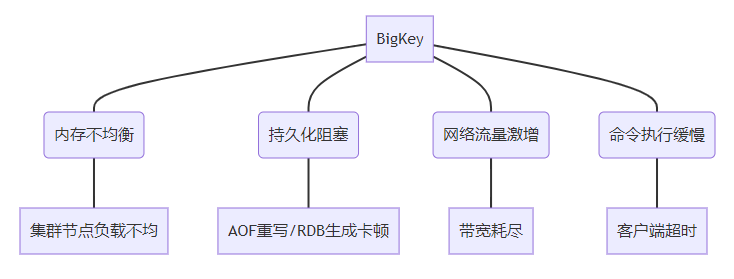
1.3 典型业务场景
| 场景 | 错误用法 | 推荐方案 |
|---|---|---|
| 社交用户画像存储 | 单个hash存储用户所有标签 | 分片存储 + 二级索引 |
| 电商购物车设计 | 单个list存储百万级商品 | 分页存储 + 冷热分离 |
| 实时消息队列 | 单个stream累积数月数据 | 按时间分片 + 定期归档 |
二、bigkey 检测方法论
2.1 内置工具检测
2.1.1 redis-cli --bigkeys
# 扫描耗时型操作,建议在从节点执行 redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.1 # 输出示例 [00.00%] biggest string found 'user:1024:info' has 12 bytes [12.34%] biggest hash found 'product:8888:spec' has 10086 fields
2.1.2 memory usage
// 计算key内存占用
long memusage = redistemplate.execute(
(rediscallback<long>) connection ->
connection.servercommands().memoryusage("user:1024:info".getbytes())
);
2.2 自定义扫描方案
2.2.1 scan + type 组合扫描
public list<map.entry<string, long>> findbigkeys(int threshold) {
list<map.entry<string, long>> bigkeys = new arraylist<>();
cursor<byte[]> cursor = redistemplate.execute(
(rediscallback<cursor<byte[]>>) connection ->
connection.scan(scanoptions.scanoptions().count(100).build())
);
while (cursor.hasnext()) {
byte[] keybytes = cursor.next();
string key = new string(keybytes);
datatype type = redistemplate.type(key);
long size = 0;
switch (type) {
case string:
size = redistemplate.opsforvalue().size(key);
break;
case hash:
size = redistemplate.opsforhash().size(key);
break;
// 其他类型处理...
}
if (size > threshold) {
bigkeys.add(new abstractmap.simpleentry<>(key, size));
}
}
return bigkeys;
}
2.2.2 rdb 文件分析
# 使用rdb-tools分析 rdb -c memory dump.rdb --bytes 10240 > bigkeys.csv # 输出示例 database,type,key,size_in_bytes,encoding,num_elements,len_largest_element 0,hash,user:1024:tags,1048576,hashtable,50000,128
2.3 监控预警体系
2.3.1 prometheus 配置
# redis_exporter配置
- name: redis_key_size
rules:
- record: redis:key_size:bytes
expr: redis_key_size{job="redis"}
labels:
severity: warning
2.3.2 grafana 看板指标
| 监控项 | 查询表达式 | 报警阈值 |
|---|---|---|
| 大key数量 | count(redis_key_size > 10240) | >10 |
| 最大key内存占比 | max(redis_key_size) / avg(…) | >5倍 |
三、bigkey 处理全流程
3.1 分治法处理
3.1.1 hash 拆分
public void splitbighash(string originalkey, int batchsize) {
map<object, object> entries = redistemplate.opsforhash().entries(originalkey);
list<list<map.entry<object, object>>> batches = lists.partition(
new arraylist<>(entries.entryset()),
batchsize
);
for (int i = 0; i < batches.size(); i++) {
string shardkey = originalkey + ":shard_" + i;
redistemplate.opsforhash().putall(shardkey,
batches.get(i).stream()
.collect(collectors.tomap(map.entry::getkey, map.entry::getvalue))
);
}
redistemplate.delete(originalkey);
}
3.1.2 list 分页
public list<object> getpaginatedlist(string listkey, int page, int size) {
long start = (page - 1) * size;
long end = page * size - 1;
return redistemplate.opsforlist().range(listkey, start, end);
}
3.2 渐进式删除
3.2.1 非阻塞删除方案
public void safedeletebigkey(string key) {
datatype type = redistemplate.type(key);
switch (type) {
case hash:
redistemplate.execute(
"hscan", key, "0", "count", "100",
(result) -> {
// 分批删除字段
return null;
});
break;
case list:
while (redistemplate.opsforlist().size(key) > 0) {
redistemplate.opsforlist().trim(key, 0, -101);
}
break;
// 其他类型处理...
}
redistemplate.unlink(key);
}
3.2.2 lua 脚本控制
-- 分批次删除hash字段
local cursor = 0
repeat
local result = redis.call('hscan', keys[1], cursor, 'count', 100)
cursor = tonumber(result[1])
for _, field in ipairs(result[2]) do
redis.call('hdel', keys[1], field)
end
until cursor == 0
3.3 数据迁移方案
3.3.1 集群环境下处理
public void migratebigkey(string sourcekey, string targetkey) {
redisclusterconnection clusterconn = redistemplate.getconnectionfactory()
.getclusterconnection();
int slot = clusterslothashutil.calculateslot(sourcekey);
redisnode node = clusterconn.clustergetnodeforslot(slot);
try (jedis jedis = new jedis(node.gethost(), node.getport())) {
// 分批迁移数据
scanparams params = new scanparams().count(100);
string cursor = "0";
do {
scanresult<map.entry<string, string>> scanresult =
jedis.hscan(sourcekey, cursor, params);
list<map.entry<string, string>> entries = scanresult.getresult();
// 分批写入新key
map<string, string> batch = entries.stream()
.collect(collectors.tomap(map.entry::getkey, map.entry::getvalue));
jedis.hmset(targetkey, batch);
cursor = scanresult.getcursor();
} while (!"0".equals(cursor));
}
}
四、java 开发规范与最佳实践
4.1 数据建模规范
| 数据类型 | 反例 | 正例 |
|---|---|---|
| string | 存储10mb的json字符串 | 拆分成多个hash + gzip压缩 |
| hash | 存储用户所有订单信息 | 按订单日期分片存储 |
| list | 存储10万条聊天记录 | 按时间分片+消息id索引 |
4.2 客户端配置优化
4.2.1 jedispool 配置
jedispoolconfig config = new jedispoolconfig(); config.setmaxtotal(200); // 最大连接数 config.setmaxwaitmillis(1000); // 最大等待时间 config.settestonborrow(true); // 获取连接时验证
4.2.2 lettuce 调优
clientoptions options = clientoptions.builder()
.autoreconnect(true)
.publishonscheduler(true)
.timeoutoptions(timeoutoptions.enabled(duration.ofseconds(1)))
.build();
4.3 监控与熔断
@circuitbreaker(name = "redisservice", fallbackmethod = "fallback")
public object getdata(string key) {
return redistemplate.opsforvalue().get(key);
}
private object fallback(string key, throwable t) {
return loadfrombackup(key);
}
五、生产环境案例
5.1 社交平台用户关系案例
问题:单个set存储50万粉丝导致节点内存溢出
解决方案:
- 按粉丝id范围拆分成100个set
- 使用sinterstore合并多个set查询
- 新增反向索引(粉丝 -> 关注列表)
5.2 电商商品属性案例
问题:hash存储10万条商品规格导致hgetall阻塞
改造方案:
- 按属性类别拆分hash
- 使用hmget获取指定字段
- 增加缓存版本号控制
六、开发方向
- ai 智能分片:基于机器学习预测数据增长趋势
- serverless 存储:自动弹性伸缩的key分片服务
- 新型数据结构:使用redisjson模块处理大文档
- 内存压缩算法:zstd 压缩算法集成优化
通过全流程的预防、检测、处理体系建设,结合智能化的监控预警,可有效应对 bigkey 挑战,保障 redis 高性能服务能力。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论