应用场景
电子发票信息提取系统主要应用于以下场景:
企业财务部门:需要处理大量电子发票,提取关键信息(如发票代码、号码、金额等)并录入财务系统。
会计事务所:在进行审计或账务处理时,需要从大量发票中提取信息进行分析。
报销管理:员工提交电子发票进行报销时,系统自动提取信息,减少人工录入错误。
档案管理:对电子发票进行分类、归档和检索时,提取的信息可以作为索引。
数据分析:从大量发票中提取数据,进行企业支出分析、税 务筹划等。
界面设计
系统采用图形化界面设计,主要包含以下几个部分:
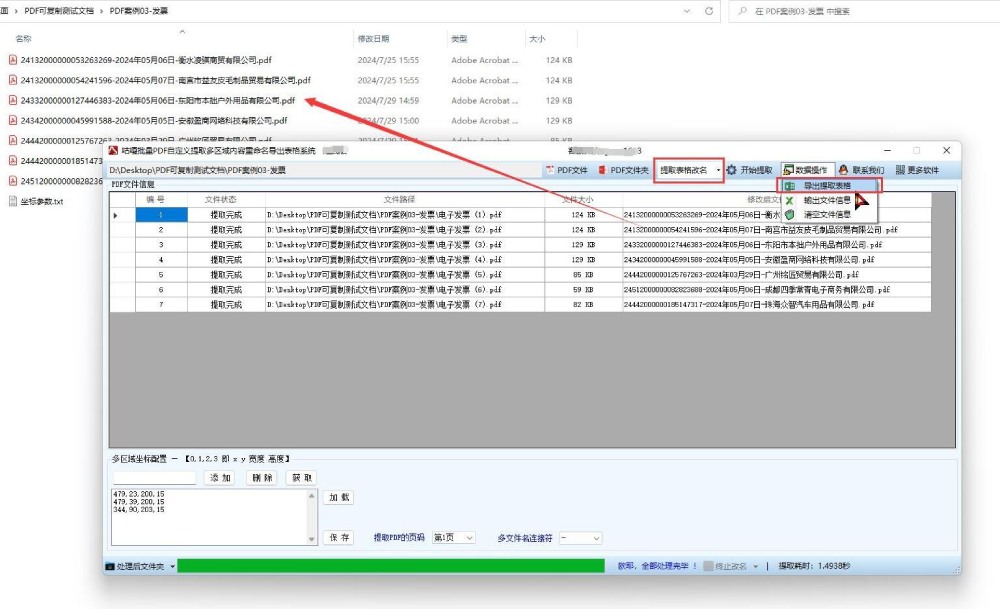
文件选择区域:提供 "选择文件" 和 "选择文件夹" 按钮,方便用户批量选择电子发票文件。
文件列表区域:显示已选择的文件列表,支持多选操作。
处理选项区域:用户可以指定输出 excel 文件的路径和名称。
进度显示区域:包含进度条和状态文本,实时显示处理进度。
操作按钮区域:提供 "开始处理"、"清空列表" 和 "退出" 等功能按钮。
界面设计简洁明了,符合用户操作习惯,同时提供了必要的提示和反馈信息。
详细代码步骤
import os
import re
import fitz # pymupdf
import pandas as pd
from pdf2image import convert_from_path
import pytesseract
from pil import image
import xml.etree.elementtree as et
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
import threading
import logging
from datetime import datetime
# 配置日志
logging.basicconfig(
level=logging.info,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
filename='invoice_extractor.log'
)
logger = logging.getlogger(__name__)
class invoiceextractor:
def __init__(self):
# 初始化配置
self.config = {
'pdf': {
'invoice_code_pattern': r'发票代码:(\d+)',
'invoice_number_pattern': r'发票号码:(\d+)',
'date_pattern': r'日期:(\d{4}年\d{1,2}月\d{1,2}日)',
'amount_pattern': r'金额:¥(\d+\.\d{2})',
'tax_pattern': r'税额:¥(\d+\.\d{2})',
'total_pattern': r'价税合计:¥(\d+\.\d{2})'
},
'ofd': {
'invoice_code_xpath': './/textobject[starts-with(text(), "发票代码")]/following-sibling::textobject[1]',
'invoice_number_xpath': './/textobject[starts-with(text(), "发票号码")]/following-sibling::textobject[1]',
'date_xpath': './/textobject[starts-with(text(), "日期")]/following-sibling::textobject[1]',
'amount_xpath': './/textobject[starts-with(text(), "金额")]/following-sibling::textobject[1]',
'tax_xpath': './/textobject[starts-with(text(), "税额")]/following-sibling::textobject[1]',
'total_xpath': './/textobject[starts-with(text(), "价税合计")]/following-sibling::textobject[1]'
}
}
def extract_pdf_info(self, pdf_path):
"""提取pdf电子发票信息"""
try:
info = {
'文件路径': pdf_path,
'发票代码': '',
'发票号码': '',
'日期': '',
'金额': '',
'税额': '',
'价税合计': ''
}
with fitz.open(pdf_path) as doc:
text = ""
for page in doc:
text += page.get_text()
# 使用正则表达式提取信息
for key, pattern in self.config['pdf'].items():
match = re.search(pattern, text)
if match:
info[key.replace('_pattern', '')] = match.group(1)
# 如果无法通过文本提取,则使用ocr
if not all(info.values()):
images = convert_from_path(pdf_path)
ocr_text = ""
for image in images:
ocr_text += pytesseract.image_to_string(image, lang='chi_sim')
for key, pattern in self.config['pdf'].items():
if not info[key.replace('_pattern', '')]:
match = re.search(pattern, ocr_text)
if match:
info[key.replace('_pattern', '')] = match.group(1)
return info
except exception as e:
logger.error(f"提取pdf {pdf_path} 信息失败: {str(e)}")
return none
def extract_ofd_info(self, ofd_path):
"""提取ofd电子发票信息"""
try:
info = {
'文件路径': ofd_path,
'发票代码': '',
'发票号码': '',
'日期': '',
'金额': '',
'税额': '',
'价税合计': ''
}
# ofd文件实际上是一个zip压缩包
# 这里简化处理,假设我们已经将ofd解压并获取到了xml文件
# 实际应用中需要处理ofd文件的解压缩和解析
# 以下代码仅为示例
# 假设我们已经获取到了ofd的xml内容
# tree = et.parse(ofd_xml_path)
# root = tree.getroot()
# for key, xpath in self.config['ofd'].items():
# element = root.find(xpath)
# if element is not none:
# info[key.replace('_xpath', '')] = element.text
# 由于ofd格式的复杂性,这里使用ocr作为替代方案
images = convert_from_path(ofd_path)
ocr_text = ""
for image in images:
ocr_text += pytesseract.image_to_string(image, lang='chi_sim')
for key, pattern in self.config['pdf'].items():
if key in info:
match = re.search(pattern, ocr_text)
if match:
info[key.replace('_pattern', '')] = match.group(1)
return info
except exception as e:
logger.error(f"提取ofd {ofd_path} 信息失败: {str(e)}")
return none
def batch_process_files(self, files, output_path):
"""批量处理文件并导出到excel"""
results = []
total = len(files)
processed = 0
for file_path in files:
try:
file_ext = os.path.splitext(file_path)[1].lower()
if file_ext == '.pdf':
info = self.extract_pdf_info(file_path)
elif file_ext == '.ofd':
info = self.extract_ofd_info(file_path)
else:
logger.warning(f"不支持的文件类型: {file_path}")
continue
if info:
results.append(info)
except exception as e:
logger.error(f"处理文件 {file_path} 时出错: {str(e)}")
processed += 1
yield processed, total
# 导出到excel
if results:
df = pd.dataframe(results)
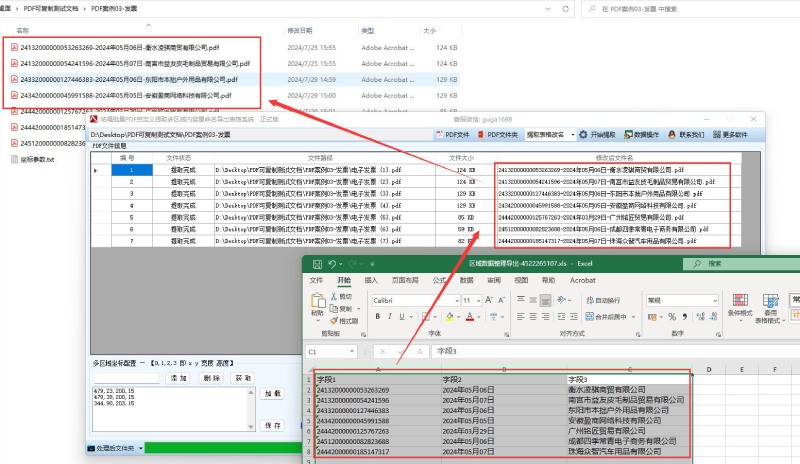
df.to_excel(output_path, index=false)
logger.info(f"成功导出 {len(results)} 条记录到 {output_path}")
return true
else:
logger.warning("没有可导出的数据")
return false
class invoiceextractorgui:
def __init__(self, root):
self.root = root
self.root.title("电子发票信息提取系统")
self.root.geometry("800x600")
self.extractor = invoiceextractor()
self.selected_files = []
self.is_processing = false
self.create_widgets()
def create_widgets(self):
"""创建gui界面"""
# 创建主框架
main_frame = ttk.frame(self.root, padding="10")
main_frame.pack(fill=tk.both, expand=true)
# 文件选择区域
file_frame = ttk.labelframe(main_frame, text="文件选择", padding="10")
file_frame.pack(fill=tk.x, pady=5)
ttk.button(file_frame, text="选择文件", command=self.select_files).pack(side=tk.left, padx=5)
ttk.button(file_frame, text="选择文件夹", command=self.select_folder).pack(side=tk.left, padx=5)
self.file_count_var = tk.stringvar(value="已选择 0 个文件")
ttk.label(file_frame, textvariable=self.file_count_var).pack(side=tk.right, padx=5)
# 文件列表区域
list_frame = ttk.labelframe(main_frame, text="文件列表", padding="10")
list_frame.pack(fill=tk.both, expand=true, pady=5)
# 创建滚动条
scrollbar = ttk.scrollbar(list_frame)
scrollbar.pack(side=tk.right, fill=tk.y)
# 创建文件列表
self.file_listbox = tk.listbox(list_frame, yscrollcommand=scrollbar.set, selectmode=tk.extended)
self.file_listbox.pack(fill=tk.both, expand=true)
scrollbar.config(command=self.file_listbox.yview)
# 处理选项区域
options_frame = ttk.labelframe(main_frame, text="处理选项", padding="10")
options_frame.pack(fill=tk.x, pady=5)
ttk.label(options_frame, text="输出文件:").pack(side=tk.left, padx=5)
default_output = os.path.join(os.getcwd(), f"发票信息_{datetime.now().strftime('%y%m%d_%h%m%s')}.xlsx")
self.output_path_var = tk.stringvar(value=default_output)
output_entry = ttk.entry(options_frame, textvariable=self.output_path_var, width=50)
output_entry.pack(side=tk.left, padx=5)
ttk.button(options_frame, text="浏览", command=self.browse_output).pack(side=tk.left, padx=5)
# 进度条区域
progress_frame = ttk.frame(main_frame, padding="10")
progress_frame.pack(fill=tk.x, pady=5)
self.progress_var = tk.doublevar(value=0)
self.progress_bar = ttk.progressbar(progress_frame, variable=self.progress_var, maximum=100)
self.progress_bar.pack(fill=tk.x)
self.status_var = tk.stringvar(value="就绪")
ttk.label(progress_frame, textvariable=self.status_var).pack(anchor=tk.w)
# 按钮区域
button_frame = ttk.frame(main_frame, padding="10")
button_frame.pack(fill=tk.x, pady=5)
self.process_button = ttk.button(button_frame, text="开始处理", command=self.start_processing)
self.process_button.pack(side=tk.left, padx=5)
ttk.button(button_frame, text="清空列表", command=self.clear_file_list).pack(side=tk.left, padx=5)
ttk.button(button_frame, text="退出", command=self.root.quit).pack(side=tk.right, padx=5)
def select_files(self):
"""选择多个文件"""
if self.is_processing:
return
files = filedialog.askopenfilenames(
title="选择电子发票文件",
filetypes=[("pdf文件", "*.pdf"), ("ofd文件", "*.ofd"), ("所有文件", "*.*")]
)
if files:
self.selected_files = list(files)
self.update_file_list()
def select_folder(self):
"""选择文件夹"""
if self.is_processing:
return
folder = filedialog.askdirectory(title="选择包含电子发票的文件夹")
if folder:
pdf_files = [os.path.join(folder, f) for f in os.listdir(folder) if f.lower().endswith('.pdf')]
ofd_files = [os.path.join(folder, f) for f in os.listdir(folder) if f.lower().endswith('.ofd')]
self.selected_files = pdf_files + ofd_files
self.update_file_list()
def update_file_list(self):
"""更新文件列表显示"""
self.file_listbox.delete(0, tk.end)
for file_path in self.selected_files:
self.file_listbox.insert(tk.end, os.path.basename(file_path))
self.file_count_var.set(f"已选择 {len(self.selected_files)} 个文件")
def browse_output(self):
"""浏览输出文件位置"""
if self.is_processing:
return
output_file = filedialog.asksaveasfilename(
title="保存输出文件",
defaultextension=".xlsx",
filetypes=[("excel文件", "*.xlsx"), ("所有文件", "*.*")]
)
if output_file:
self.output_path_var.set(output_file)
def clear_file_list(self):
"""清空文件列表"""
if self.is_processing:
return
self.selected_files = []
self.update_file_list()
def start_processing(self):
"""开始处理文件"""
if self.is_processing or not self.selected_files:
return
output_path = self.output_path_var.get()
if not output_path:
messagebox.showerror("错误", "请指定输出文件")
return
# 确认是否覆盖现有文件
if os.path.exists(output_path):
if not messagebox.askyesno("确认", "输出文件已存在,是否覆盖?"):
return
self.is_processing = true
self.process_button.config(state=tk.disabled)
self.status_var.set("正在处理...")
# 在单独的线程中处理文件
threading.thread(target=self.process_files_thread, daemon=true).start()
def process_files_thread(self):
"""文件处理线程"""
try:
output_path = self.output_path_var.get()
progress = 0
total = len(self.selected_files)
for processed, total in self.extractor.batch_process_files(self.selected_files, output_path):
progress = (processed / total) * 100
self.progress_var.set(progress)
self.status_var.set(f"正在处理 {processed}/{total}")
self.root.update_idletasks()
self.progress_var.set(100)
self.status_var.set("处理完成")
messagebox.showinfo("成功", f"已成功处理 {total} 个文件\n结果已保存至: {output_path}")
except exception as e:
logger.error(f"处理过程中出错: {str(e)}")
self.status_var.set("处理出错")
messagebox.showerror("错误", f"处理过程中出错: {str(e)}")
finally:
self.is_processing = false
self.process_button.config(state=tk.normal)
def main():
"""主函数"""
try:
# 检查依赖库
import pymupdf
import pandas
import pdf2image
import pytesseract
from pil import image
# 创建gui
root = tk.tk()
app = invoiceextractorgui(root)
root.mainloop()
except importerror as e:
print(f"缺少必要的库: {str(e)}")
print("请安装所有依赖库: pip install pymupdf pandas pdf2image pytesseract pillow")
except exception as e:
print(f"程序启动出错: {str(e)}")
logger.error(f"程序启动出错: {str(e)}")
if __name__ == "__main__":
main() 系统实现主要包含以下几个核心模块:
配置管理:设置 pdf 和 ofd 文件的信息提取规则,包括正则表达式模式和 ofd 的 xpath 表达式。
pdf 信息提取:使用 pymupdf 库读取 pdf 文本内容,通过正则表达式提取关键信息;如果文本提取失败,则使用 ocr 技术进行图像识别。
ofd 信息提取:ofd 文件结构复杂,本系统采用 ocr 技术作为主要提取方法,将 ofd 转换为图像后使用 pytesseract 进行文字识别。
批量处理:支持批量处理多个文件,并提供进度反馈。
数据导出:将提取的信息整理成 dataframe,并导出为 excel 文件。
图形界面:使用 tkinter 构建直观易用的图形界面,支持文件选择、处理选项设置和进度显示。
总结优化
该系统提供了一个基础的电子发票信息提取解决方案,具有以下优点:
- 通用性:支持 pdf 和 ofd 两种主流电子发票格式。
- 可扩展性:配置文件分离,易于添加新的发票格式或修改提取规则。
- 用户友好:图形界面操作简单,适合非技术人员使用。
- 日志记录:完整的日志记录,便于问题排查和系统优化。
然而,系统仍有以下可以优化的地方:
- ofd 解析:当前使用 ocr 处理 ofd 文件效率较低,可以研究更高效的 ofd 解析库。
- 提取规则优化:针对不同类型的发票,可能需要定制化的提取规则,可考虑添加规则配置界面。
- 性能优化:对于大量文件的处理,可以引入多线程或异步处理提高效率。
- 数据验证:增加提取信息的验证机制,提高数据准确性。
- 用户体验:添加更多交互反馈,如文件预览、处理结果预览等功能。
通过不断优化和扩展,该系统可以满足更多场景的需求,提高电子发票信息处理的效率和准确性。
到此这篇关于python实现pdf电子发票信息提取到excel表格的文章就介绍到这了,更多相关python提取pdf信息保存到excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论