前言
假如你有一个word模版文档,要在里面填写人员信息,但人员有成百上千个,手动填起来太浪费时间,还容易弄错,刚好你又会写python,请看下文
一、需要安装的库
操作word的库 docx
pip install docx
转pdf的库 win32com,在python中是安装pywin32
pip install pywin32
二、核心逻辑-替换
(1)获取需要填入的数据,大部分情况是excel(用pandas读取方便)或json
(2)在word中需要填写的位置填上唯一标识的字符串(尽量短,比如我之前用name,结果被拆分成了n和ame),用代码打开word,找到这个唯一标识的字符串,和原数据进行替换操作,重新保存即可
(3)转为pdf就很简单了
替换word内容代码如下:
from docx import document
import pandas as pd
import json
def replacetext(wb, t, value):
for x in wb.paragraphs:
if t in x.text: # t 尽量短,一个最好,不然这里可能会被拆分 如果替换失败 debug这里查看x.text
inline = x.runs # t 修改runs中的字符串 可以保留格式
for i in range(len(inline)):
if t in inline[i].text:
text = inline[i].text.replace(t, str(value))
inline[i].text = text
for table in wb.tables: # 遍历文档中的所有表格
for row in table.rows: # 遍历表格中的所有行
for cell in row.cells: # 遍历行中的所有单元格
if t in cell.text:
for paragraph in cell.paragraphs:
if t in paragraph.text:
inline = paragraph.runs
for i in range(len(inline)):
if t in inline[i].text:
text = inline[i].text.replace(t, str(value))
inline[i].text = text
# word表格居中:在字符串前面拼空格 这里的11是表格不换行的情况下最长可输入的字符数
def getcentertext(text):
text = text.replace(' ', '')
for i in range(11 - len(text)):
text = " " + text
return text
# 程序入口
if __name__ == '__main__':
# loan_data = pd.read_excel(r"c:\users\administrator\desktop\排名\汇总.xlsx",
# sheet_name="sheet1", header=0, names=none, index_col=0)
# jsonstr = loan_data.to_json(orient='records', force_ascii=false)
loan_data = [
{"ame": "张三", "xx": "优秀"},
{"ame": "李四", "xx": "良好"}
]
for j in loan_data:
wb = document(r"c:\users\administrator\desktop\排名\模版.docx")
replacetext(wb, 'ame', j.get('ame')) # 把word中的ame替换成张三、李四
replacetext(wb, 'xx', getcentertext(j.get('xx'))) # 如果是表格数据要居中
wb.save(r"c:\users\administrator\desktop\排名\结果(%s).docx" % j.get('ame'))
print(j.get('ame'))
print("完成")
转为pdf代码如下:
from win32com.client import dispatch
from os import walk
wdformatpdf = 17
def doc2pdf(input_file):
word = dispatch('word.application')
doc = word.documents.open(input_file)
doc.saveas(input_file.replace(".docx", ".pdf"), fileformat=wdformatpdf)
doc.close()
word.quit()
# 程序入口
if __name__ == '__main__':
# 把此文件夹下所有的word文档转为pdf
directory = "c:\\users\\administrator\\desktop\\排名"
for root, dirs, filenames in walk(directory):
for file in filenames:
print(file)
if file.endswith(".doc") or file.endswith(".docx"):
doc2pdf(str(root + "\\" + file))
print("全部完成")
三、知识延展
使用python不改变格式的情况下批量替换word里面的内容
需要使用如$name,${id}这样的模板
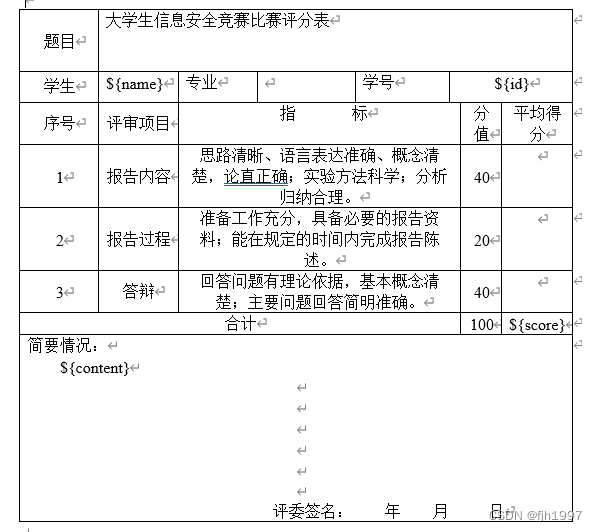
实现代码
import os
import io
from python_docx_replace import docx_replace,docx_get_keys
from docx import document
from random import randrange
student_list='''1,张三,2202330301
2,李四,2202330302
3,王五,2202330303
'''
review=["思路清晰、语言表达准确,整体表现良好",",准备工作一般,整体表现良好","思路清晰、语言表达一般、回答问题有理论依据,","有个别格式不对的需要修改。"]
score=['70', '88', '81']
students=student_list.split("\n")
# print(students)
students_dict_array=[]
for student in students:
student_dict={}
student_dict["name"]=student.split(",")[1]
student_dict["sid"]=student.split(",")[2]
students_dict_array.append(student_dict)
print(students_dict_array)
# 图片存放的路径
path = "c:\\baidusyncdisk\\大学生信息安全竞赛评分表\\"
def alter(file,name,id,num):
"""
替换文件中的字符串
:param file:文件名
:param old_str:就字符串
:param new_str:新字符串
:return:
"""
doc = document(file)
keys = docx_get_keys(doc) # let's suppose the word document has the keys: ${name} and ${phone}
print(keys) # ['name', 'phone']
# call the replace function with your key value pairs
docx_replace(doc, name=name,id=id,content=review[randrange(len(review))],score=score[num])
doc.save(os.path.join(path,"new",file))
# 遍历更改文件名
num = 0
for file in os.listdir(path):
alter(os.path.join(path,file),students_dict_array[num]["name"],students_dict_array[num]["sid"],num)
os.rename(os.path.join(path,file),os.path.join(path,"选手-"+students_dict_array[num]["sid"][-2:]+students_dict_array[num]["name"]+"-记录表")+".doc")
num = num + 1
到此这篇关于python如何动态修改word文档内容并保留格式样式的文章就介绍到这了,更多相关python修改word内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论