在开发组件库的过程中,文档无疑是不可或缺的一环。优质的文档可以极大地提高组件库的可用性和可维护性。然而,传统的文档编写和维护方式通常是一项耗时且繁琐的任务。这些传统文档生成工具通常基于javascript开发,速度上并没有明显的优势。
在本文中,我将尝试将go语言与前端技术巧妙融合,以创建一款能在毫秒级别完成文档生成的工具。
鉴于代码量庞大,本文中的代码部分将主要以函数签名和注释的形式呈现,而不涉及具体实现细节。我们将深入研究以下六个主要部分:
- 命令行工具: 文档生成的启动入口。
- 任务流管理(并行串行任务): 高效地管理文档生成任务,包括并行和串行执行。
- markdown文档解析: 从markdown格式的文档中提取信息并转化为可用的html格式。
- 文档元数据收集: 从文档中提取关键元数据,如位置信息,排序信息,分类信息。
- 文档锚点: 用于导航和快速跳转的锚点,提升用户体验。
- 文档生成: 最终生成组件库文档的核心部分。
命令行工具
为了确保我们的生成工具能够轻松地进行打包和使用,我将其设计成了一个命令行工具。这使得将来可以方便地将工具包装成npm包。我选择了使用github.com/spf13/cobra库来构建命令行工具,以便更好地管理命令和参数。
相关代码如下:
var rootcommand = &cobra.command{
use: "nk",
short: "nk: 一个神奇的文档生成工具",
long: "nk是一个强大的文档生成工具,旨在提供快速而高效的文档生成体验。",
}
var generatecommand = &cobra.command{
use: "generate",
aliases: []string{"g"},
short: "generate: 启动文档生成",
long: "generate命令用于启动文档生成。",
}
var doccommand = &cobra.command{
use: "doc",
short: "generate doc project: 生成文档项目",
long: "doc命令用于生成文档项目。",
run: rundoccommand,
}
func initdoccommand() {
wd, err := os.getwd()
if err != nil {
return
}
// 声明命令参数
doccommand.flags().string("components-dir", path.join(wd, "projects", "components"), "指定组件目录的绝对路径")
doccommand.flags().string("doc-dir", path.join(wd, "projects", "design-doc"), "指定设计文档目录的绝对路径")
doccommand.flags().string("docs-dir", path.join(wd, "docs"), "指定文档目录的绝对路径")
doccommand.flags().bool("watch", true, "监听文件变化")
}
func init() {
initdoccommand()
generatecommand.addcommand(doccommand)
generatecommand.addcommand(servicecommand)
generatecommand.addcommand(staticiconscommand)
rootcommand.addcommand(generatecommand)
}在上述代码中,我们对命令和参数进行了更具描述性的命名,以便开发者更容易理解其功能。同时,我们还添加了关于工具的简短和长描述,以提供更多上下文信息。这将有助于用户更好地理解如何使用这个命令行工具以及它的目标。
这样我们就可以运行类似如下命令了:
nx g doc --components-dir xxxx
任务流管理
在这个工具中我们可以拆分很多子任务,有的任务需要依赖其他任务的完成,有的任务没有执行顺序可以并行运行,所以需要一个很好的任务流管理工具来帮助我们来管理这些子任务
主要代码如下:
type task struct {
name string // 任务名称
work func() error // 任务执行的函数
dependencies []*task // 依赖的任务
mu sync.mutex // 互斥锁,用于同步
cond *sync.cond // 条件变量,用于等待任务完成
done bool // 任务完成标志
starttime time.time // 任务开始时间
endtime time.time // 任务结束时间
nooutputlog bool // 是否输出日志
}
// printexecutiontime 输出任务执行时间
func printexecutiontime(task *task) {
executiontime := task.endtime.sub(task.starttime).milliseconds()
color.green.println(fmt.sprintf("[%s] 任务完成 执行时间:%d 毫秒", task.name, executiontime))
}
// newtask 创建一个新任务
func newtask(name string, work func() error) *task {
task := &task{
name: name,
work: work,
done: false,
}
task.cond = sync.newcond(&task.mu)
return task
}
// setdependency 设置任务的依赖关系
func (t *task) setdependency(dependencies ...*task) {
t.dependencies = append(t.dependencies, dependencies...)
}
// waitfordependencies 等待任务的依赖任务完成
func (t *task) waitfordependencies() {
for _, dep := range t.dependencies {
dep.waitforcompletion()
}
}
// run 运行任务
func (t *task) run() error {
t.waitfordependencies()
t.mu.lock()
defer t.mu.unlock()
t.starttime = time.now()
if !t.nooutputlog {
color.green.println(fmt.sprintf("[%s] 任务开始", t.name))
}
err := t.work()
if err != nil {
return err
}
t.endtime = time.now()
t.done = true
if !t.nooutputlog {
printexecutiontime(t)
}
t.cond.broadcast()
return nil
}
// waitforcompletion 等待任务完成
func (t *task) waitforcompletion() {
t.mu.lock()
defer t.mu.unlock()
for !t.done {
t.cond.wait()
}
}
// serialtask 串行执行任务
func serialtask(tasks []*task) {
for _, task := range tasks {
task.run()
}
}
// paralleltask 并行执行任务
func paralleltask(tasks []*task) {
var wg sync.waitgroup
for _, task := range tasks {
wg.add(1)
go func(t *task) {
defer wg.done()
t.run()
}(task)
}
wg.wait()
}通过上述简单封装,我们可以这样使用轻松管理子任务的执行
var clearcachetask = flows.newtask("清除项目缓存", func() error {
return nil
})
var copyprojecttask = flows.newtask("复制项目模板", func() error {
return nil
})
// 设置依赖 copyprojecttask 依赖 clearcachetask任务
copyprojecttask.setdependency(clearcachetask)
var collecttemplatemetatask = flows.newtask("收集模板信息", func() error {
return nil
})
flows.paralleltask([]*flows.task{
clearcachetask,
copyprojecttask,
collecttemplatemetatask,
})
上述示例中clearcachetask, copyprojecttask, collecttemplatemetatask 这三个任务会并行运行,不过copyprojecttask依赖了clearcachetask,需要等clearcachetask执行完成才会真正执行。
markdown文档解析
在组件库文档中,markdown(md)文档通常占据着相当大的比例。这些文档不仅包括了示例代码,还包括了组件库的介绍、使用指南、组件api等内容。为了处理这些markdown文档,我们使用了 github.com/yuin/goldmark 这个工具库。本节将详细介绍如何使用它来将markdown文档转换为html格式。
核心代码如下;
func converttohtml(markdowncontent string) string {
var htmloutput bytes.buffer
md := goldmark.new(
goldmark.withextensions(extension.gfm), // 支持github风格的markdown
// 如果需要语法高亮,可以启用以下代码(需要配置chroma等选项)
//goldmark.withextensions(
// highlighting.newhighlighting(
// highlighting.withstyle("github"),
// highlighting.withformatoptions(
// chromahtml.withclasses(true),
// ),
// ),
//),
goldmark.withrenderer(htmlrenderer()), // 使用自定义的html渲染器
goldmark.withrendereroptions(html.withunsafe()), // 允许html渲染器输出不安全的html
)
if err := md.convert([]byte(markdowncontent), &htmloutput); err != nil {
panic(err)
}
return htmloutput.string()
}需要注意的是, 我们启用了 html.withunsafe() 选项, 如果不开启的话,默认情况下,goldmark 不会呈现原始 html 或潜在危险的链接
这段核心代码演示了如何使用github.com/yuin/goldmark库将markdown文档内容转换为html格式。它首先创建了一个goldmark实例,配置了一些扩展(例如支持github风格的markdown和语法高亮),然后将markdown内容传递给md.convert函数,最终将转换后的html输出到htmloutput缓冲区中。
如果需要语法高亮,可以根据需要取消注释相关部分,并进行相应的配置。
markdown文档解析是生成组件库文档的重要一步,它使我们能够将markdown格式的文档转换为易于阅读和导航的html格式,为用户提供了更好的文档浏览体验。
这段代码中使用了自定义html渲染器,自定义渲染器主要对md标签进行了特殊定制,转换html时,h标签上需要携带id,方便后续的文档锚点进行锚点导航。
核心代码如下:
// customhtmlrenderer 自定义渲染器
type customhtmlrenderer struct {
html.renderer
}
func htmlrenderer() renderer.renderer {
return renderer.newrenderer(renderer.withnoderenderers(util.prioritized(newrenderer(), 1000)))
}
func newrenderer(opts ...html.option) renderer.noderenderer {
r := &customhtmlrenderer{
renderer: html.renderer{
config: html.newconfig(),
},
}
for _, opt := range opts {
opt.sethtmloption(&r.config)
}
return r
}
// renderheading 自定义标签渲染
func (r *customhtmlrenderer) renderheading(
w util.bufwriter, source []byte, node ast.node, entering bool) (ast.walkstatus, error) {
n := node.(*ast.heading)
if entering {
lines := n.baseblock.lines()
if lines.len() > 0 {
at := n.baseblock.lines().at(0)
buf := at.value(source)
// 附加id
n.setattribute([]byte("id"), buf)
}
_, _ = w.writestring("<h")
_ = w.writebyte("0123456"[n.level])
if n.attributes() != nil {
html.renderattributes(w, node, html.headingattributefilter)
}
_ = w.writebyte('>')
} else {
_, _ = w.writestring("</h")
_ = w.writebyte("0123456"[n.level])
_, _ = w.writestring(">\n")
}
return ast.walkcontinue, nil
}
func (r *customhtmlrenderer) registerfuncs(reg renderer.noderendererfuncregisterer) {
r.renderer.registerfuncs(reg)
// 注册 覆盖内置的标题渲染逻辑
reg.register(ast.kindheading, r.renderheading)
}
文档元数据收集
在将markdown文档渲染为html并呈现在页面上时,我们需要了解渲染的位置、顺序、语言、标题等重要信息。为了实现这一目标,通常在markdown文档的开头声明这些信息。例如:
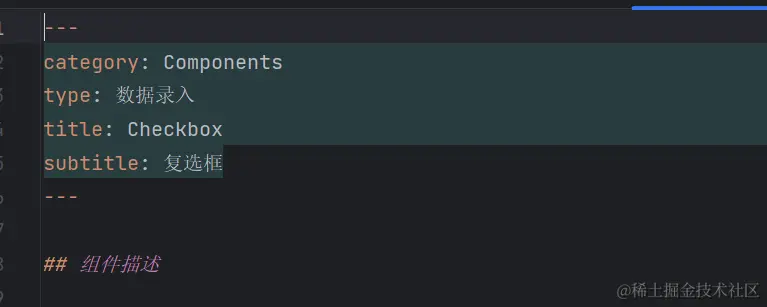
因此,我们需要收集并汇总这些元数据,以供后续文档生成使用。
以下是核心代码示例,配有详细的注释:
func parsemarkdown(filepath string) (*document, error) {
// 读取markdown文件内容
mdcontent, err := ioutil.readfile(filepath)
if err != nil {
return nil, err
}
// 使用正则表达式提取yaml元数据部分
re := regexp.mustcompile(`---\r*\n([\s\s]*?)\r*\n---`)
match := re.findstringsubmatch(string(mdcontent))
if len(match) < 2 {
return nil, fmt.errorf("yaml section not found")
}
// 获取yaml元数据内容
yamlcontent := match[1]
// 获取除去yaml元数据的markdown内容
markdowncontent := string(mdcontent)[len(yamlcontent)+8:]
// 解析yaml元数据
var metadata metadata
if err := yaml.unmarshal([]byte(yamlcontent), &metadata); err != nil {
return nil, fmt.errorf("error parsing yaml: %w", err)
}
// 获取文件名(包括扩展名)
filenamewithextension := filepath.base(filepath)
// 去除扩展名,获得文件名
filename := strings.trimsuffix(filenamewithextension, filepath.ext(filenamewithextension))
// 创建文档对象,包括元数据和多语言html内容
document := document{
metadata: metadata,
zhcn: converttohtml(getsectioncontent(markdowncontent, "zh-cn")),
enus: converttohtml(getsectioncontent(markdowncontent, "en-us")),
filekey: filename,
}
return &document, nil
}这段核心代码演示了如何从markdown文档中提取yaml格式的元数据部分,并将其解析为元数据对象。随后,代码将markdown文档内容分成不同语言的部分,并将其转换为html格式。
文档元数据收集是文档生成过程中的关键步骤,它允许我们获取文档的关键信息,如标题、语言等,以便更好地呈现文档内容。这些信息将对后续文档生成和导航起到至关重要的作用。
文档锚点
文档锚点是一种重要的导航工具,它们可以帮助用户快速跳转到文档中的特定部分。在组件库文档中,文档锚点特别有用,因为它们使用户能够快速找到他们需要的信息,提高了文档的可读性和可用性。
核心代码如下:
func wrapperanchor(content string, anchor string) string {
return fmt.sprintf(
"<div class="doc-content">\n\t\t%s\n</div><nx-anchor container="#component-demo">%s</nx-anchor>", content, anchor)
}
// ...
templatestring += wrapperanchor(angularnonbindable(templatecontent), strings.join(anchorlink, "\n"))
anchorlink 是从前面收集的元数据解析而来
文档生成
文档生成是组件库文档工具的核心部分,它负责将收集到的元数据、markdown文档解析结果和文档锚点整合在一起,最终生成用户友好的组件库文档。在这一章节中,我们将讨论如何使用go语言来实现文档生成的关键功能。首先,让我们来了解文档生成的一般流程。
文档生成通常包括以下主要步骤:
- 收集元数据: 获取组件库中的各个文档的元数据,包括标题、语言、作者等信息。
- markdown文档解析: 将markdown文档解析为html格式,以便用户可以在页面上浏览和交互。
- 创建文档锚点: 在文档中创建锚点,以便用户可以轻松导航和快速跳转到感兴趣的部分。
- 整合内容: 将元数据、markdown解析结果和锚点整合在一起,构建完整的组件库文档。
- 生成html页面: 最终,将整合后的文档转换为html页面,并提供用户友好的界面。
核心代码如下:
// registrationtask 注册相关子任务&处理任务之间的依赖关系
func (receiver *compiledoctask) registrationtask() {
// 创建清除 design-doc 任务
receiver.cleardesigndoctask = flows.newtask("清除 design-doc", receiver.cleartaskhandler)
// 创建复制 design-doc 任务
receiver.copydesigndoctask = flows.newtask("复制 design-doc", receiver.copydocprojecttaskhandler)
// 设置复制任务依赖于清除任务
receiver.copydesigndoctask.setdependency(receiver.cleardesigndoctask)
// 创建收集全局文档信息任务
receiver.collectglobaldocstask = flows.newtask("收集全局文档信息", receiver.collectglobaldocstaskhandler)
// 创建收集组件文档信息任务
receiver.collectcomponentdocstask = flows.newtask("收集组件文档信息", receiver.collectcomponentdocstaskhandler)
// 创建生成全局文档任务
receiver.generateglobaldocstask = flows.newtask("生成全局文档", receiver.generateglobaldocstaskhandler)
// 设置生成全局文档任务依赖于复制和收集任务
receiver.generateglobaldocstask.setdependency(
receiver.copydesigndoctask,
receiver.collectglobaldocstask,
)
// 创建生成demo文档任务
receiver.generatedemodocstask = flows.newtask("生成demo文档", receiver.generatedemodocstaskhandler)
// 设置生成demo文档任务依赖于收集组件文档信息任务
receiver.generatedemodocstask.setdependency(receiver.collectcomponentdocstask)
}
// compiletask 编译文档 处理元数据收集,md文档解析等
func (receiver *compiledoctask) compiletask() {
// 并行执行清除、复制、收集任务
flows.paralleltask([]*flows.task{
receiver.cleardesigndoctask,
receiver.copydesigndoctask,
receiver.collectcomponentdocstask,
receiver.collectglobaldocstask,
})
}
// generatetask 将收集的信息整合到一起生成完整的组件库文档
func (receiver *compiledoctask) generatetask() {
// 并行执行生成全局文档和生成demo文档任务
flows.paralleltask([]*flows.task{
receiver.generateglobaldocstask,
receiver.generatedemodocstask,
})
}
func rundoccommand(cmd *cobra.command, _ []string) {
componentsdir, _ := cmd.flags().getstring("components-dir")
docdir, _ := cmd.flags().getstring("doc-dir")
docsdir, _ := cmd.flags().getstring("docs-dir")
watch, _ := cmd.flags().getbool("watch")
sourcedir := path.join("design-doc") // 源目录
// 创建文档生成任务
compiledoctask := newcompiledoctask(componentsdir, docdir, docsdir, sourcedir)
// 执行编译任务
compiledoctask.compiletask()
// 执行生成任务
compiledoctask.generatetask()
if watch {
// 监听单个文件的变化 实现局部更新
watchdoc(cmd, compiledoctask)
}
}在这个示例中,我们首先创建了文档生成任务并注册了相关的子任务以及它们之间的依赖关系。然后,我们展示了如何执行编译任务和生成任务
生成结果如下:
使用效果
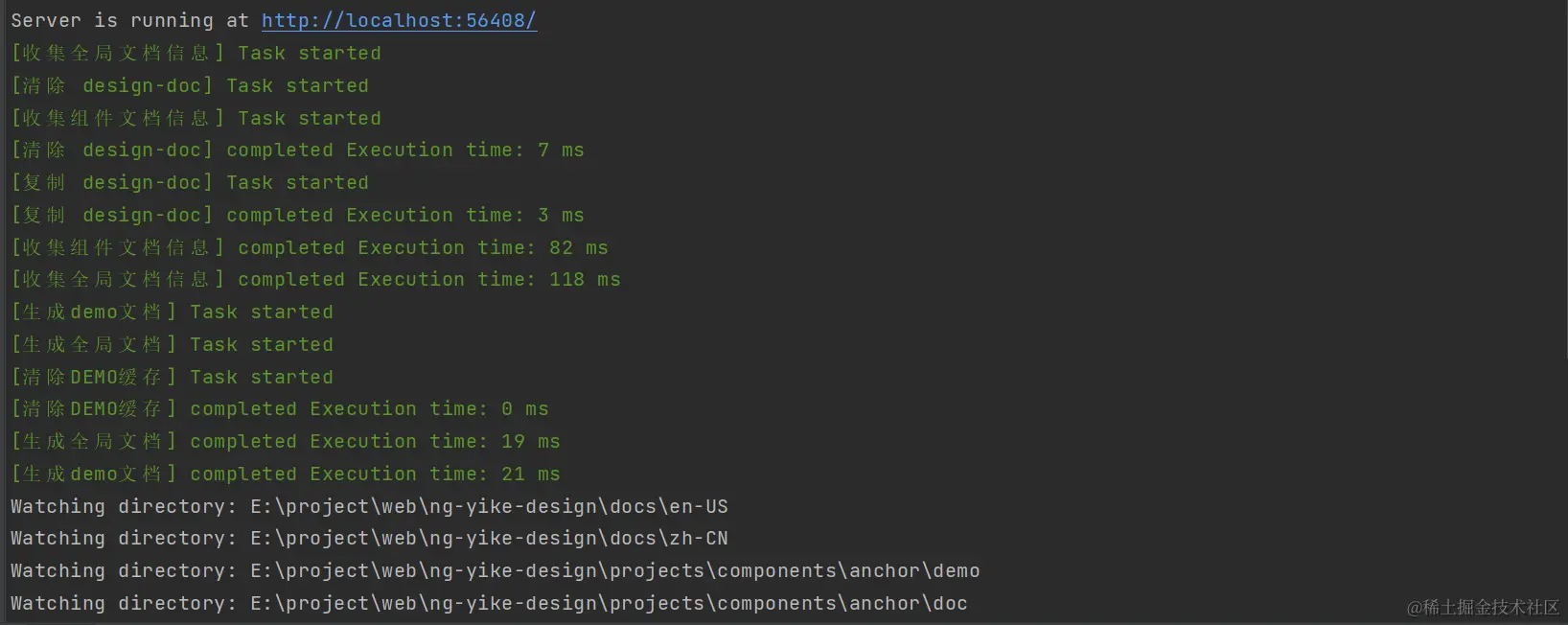
生成速度
整体下来300ms不到就生成了完整的组件库文档了
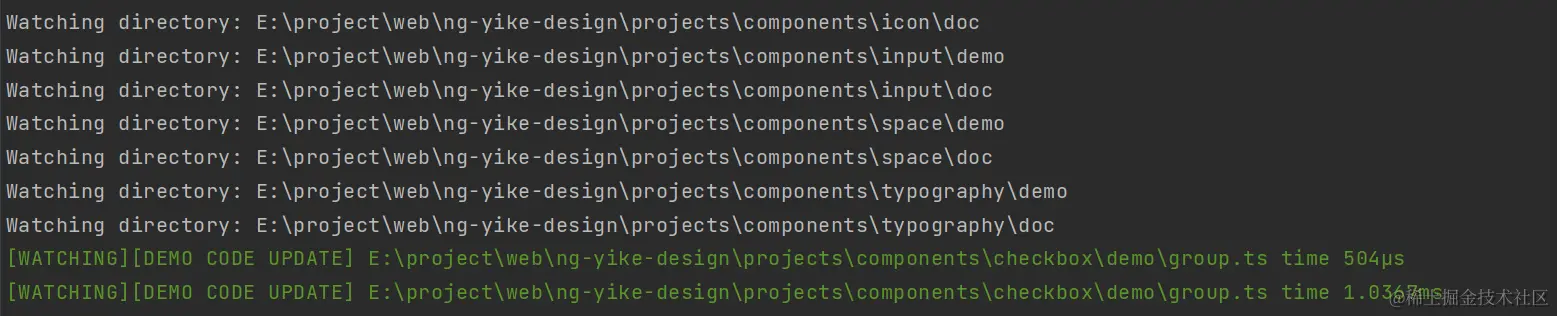
局部更新
可以看到修改group.ts文件触发更新所需时间也是非常快的
总结
本文介绍了一款强大的组件库文档生成工具,使用go语言作为开发语言。该工具旨在提高组件库文档的可用性和可维护性,同时也力求提供毫秒级的文档生成体验。通过本文,我们深入探讨了工具的各个方面,包括命令行工具、任务流管理、markdown文档解析、文档元数据收集、文档锚点以及文档生成等关键特性。
源码链接
你可以在以下链接找到完整的源代码和工具的实现细节:
关键功能和步骤
- 命令行工具: 我们使用go语言的
github.com/spf13/cobra库创建了一个命令行工具,使工具能够以包装的方式轻松使用。 - 任务流管理: 我们实现了任务流管理,支持并行和串行任务,以有效管理异步任务的执行顺序。
- markdown文档解析: 使用
github.com/yuin/goldmark库,我们能够将markdown文档转换为html,以便用户可以在页面上浏览和交互。 - 文档元数据收集: 工具可以从markdown文档中收集元数据,包括标题、语言、作者等信息,以供后续文档生成使用。
- 文档锚点: 我们讨论了如何在markdown文档中创建文档锚点,以帮助用户快速导航到感兴趣的部分。
- 文档生成: 最后,我们介绍了文档生成的流程,包括任务的注册、依赖管理和并行执行,以将元数据、markdown解析结果和锚点整合为用户友好的组件库文档。
这个组件库文档生成工具可以大大简化文档编写和维护的工作,并提供出色的文档浏览体验。通过深入了解本文所述的关键特性和源代码,您可以定制并集成这个工具到您的项目中,提升组件库文档的质量和效率。
以上就是使用go语言编写一个毫秒级生成组件库文档工具的详细内容,更多关于go组件库文档工具的资料请关注代码网其它相关文章!





发表评论