在网站的数据分析中,pv(page view,页面浏览量)和 uv(unique visitor,独立访客数)是两个重要的指标,几乎每个网站都需要对其进行统计。市面上有很多成熟的统计产品,例如百度的站点统计功能,而本文将介绍如何借助 redis 的计数器功能,实现一套属于自己的站点统计服务。
1 方案设计
1.1 术语说明
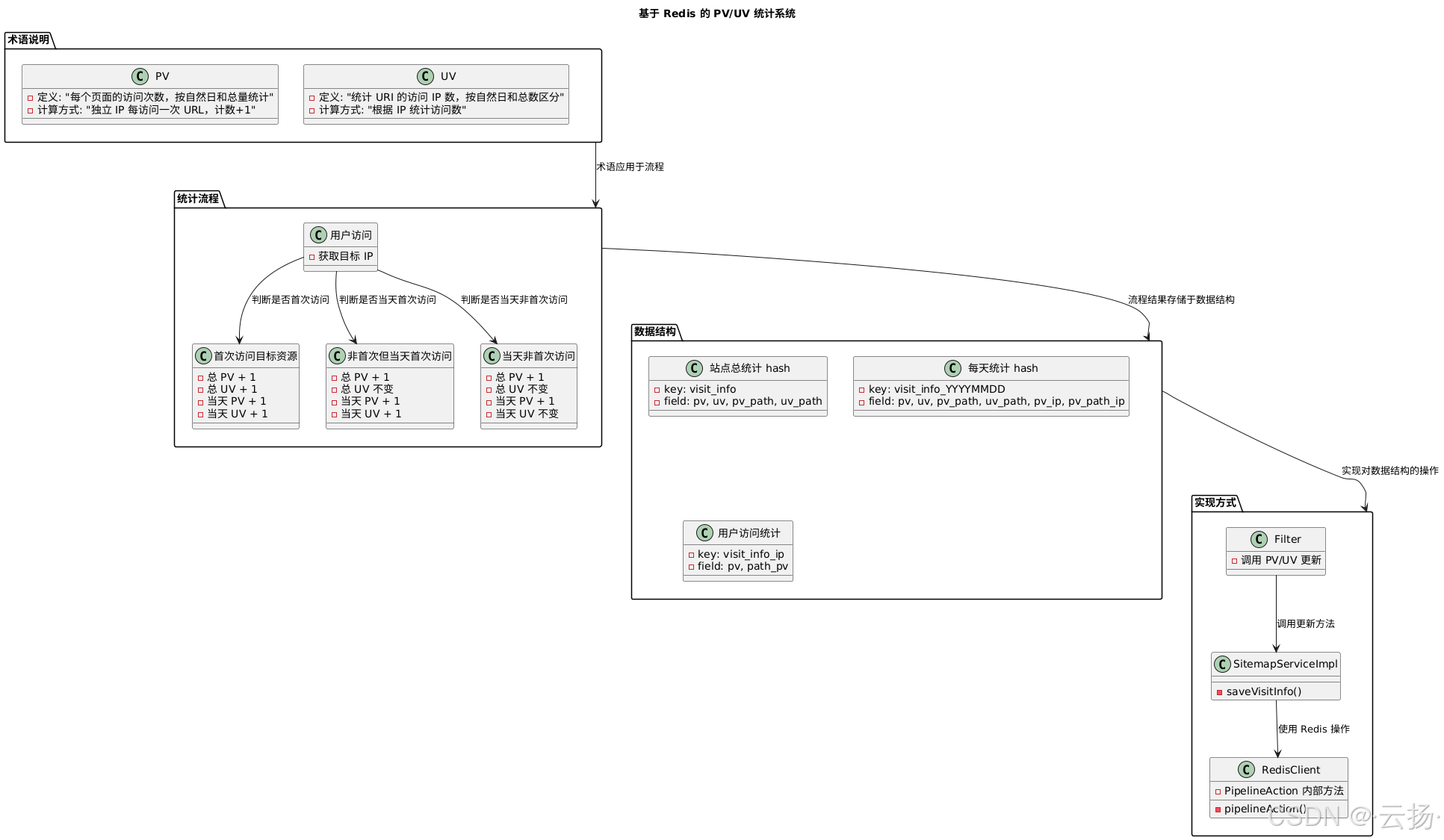
在我们的实际实现中,对 pv 和 uv 的定义与标准定义存在一定差异:
- pv(page view):指的是每个页面的访问次数。在本服务中,pv 是总量概念,一个独立的 ip 每访问一次 url,对应的访问计数就加 1。我们希望按自然日统计每个 url 的访问计数,同时也能统计总的访问计数,以此判断哪些页面更受读者喜爱。
- uv(unique visitor):用于统计 uri 的访问 ip 数,同样按照自然日和总数进行区分。
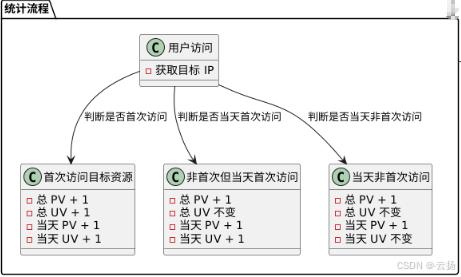
1.2 统计流程
用户访问时,首先获取目标 ip,然后根据其访问情况更新对应的计数:
- 首次访问目标资源:总 pv 加 1,总 uv 加 1;当天 pv 加 1,当天 uv 加 1。
- 非首次访问,但为当天第一次访问:总 pv 加 1,总 uv 不变;当天 pv 加 1,当天 uv 加 1。
- 当天非首次访问:总 pv 加 1,总 uv 不变;当天 pv 加 1,当天 uv 不变。
1.3 数据结构
我们使用 redis 的 hash 来存储访问信息,具体需要存储以下三类信息:
- 站点的总访问信息:包括站点的 pv/uv,以及每个 uri 的 pv/uv。
- 某一天的访问信息:涵盖某一天站点的总访问 pv/uv,以及某一天每个 uri 的 pv/uv。由于计算 uv 时需要存储用户是否访问过某个资源的信息,所以额外添加了存储单元保存用户访问历史。
- 用户的访问信息:包含用户访问站点的总次数,以及访问每个 uri 的总次数。用户每天的访问信息存储在每天的访问信息结构中,因为每天的访问信息通常不需要持久化保存,比如只存储最近一个月的情况,可设置 redis 的有效期为 30 天,到期自动清除。
完整的 hash 定义如下:
- 站点总统计 hash:
- key:visit_info
- field:
- pv:站点的总 pv
- uv:站点的总 uv
- pv_path:站点某个资源的总访问 pv
- uv_path:站点某个资源的总访问 uv
- 每天统计 hash:
- key:visit_info_20230822(每日记录,一天一条记录)
- field:
- pv:12(field = 月日_pv,pv 的计数)
- uv:5(field = 月日_uv,uv 的计数)
- pv_path:2(资源的当前访问计数)
- uv_path:资源的当天访问 uv
- pv_ip:用户当天的访问次数
- pv_path_ip:用户对资源的当天访问次数
- 用户访问统计:
- key:visit_info_ip
- field:
- pv:用户访问的站点总次数
- path_pv:用户访问的路径总次数

2 实现方式
2.1 统计计数
核心计数的实现路径为 com.github.paicoding.forum.service.sitemap.service.sitemapserviceimpl#savevisitinfo。其原理是:用户站点总 pv 加 1,若返回的最新计数是 1,表示是站点的新用户,所有 uv 加 1;今日 pv 加 1,若返回的最新计数是 1,表示当前用户今日首次访问,进入的 uv 加 1 。
/**
* 保存站点数据模型
* <p>
* 站点统计hash:
* - visit_info:
* ---- pv: 站点的总pv
* ---- uv: 站点的总uv
* ---- pv_path: 站点某个资源的总访问pv
* ---- uv_path: 站点某个资源的总访问uv
* - visit_info_ip:
* ---- pv: 用户访问的站点总次数
* ---- path_pv: 用户访问的路径总次数
* - visit_info_20230822每日记录, 一天一条记录
* ---- pv: 12 # field = 月日_pv, pv的计数
* ---- uv: 5 # field = 月日_uv, uv的计数
* ---- pv_path: 2 # 资源的当前访问计数
* ---- uv_path: # 资源的当天访问uv
* ---- pv_ip: # 用户当天的访问次数
* ---- pv_path_ip: # 用户对资源的当天访问次数
*
* @param visitip 访问者ip
* @param path 访问的资源路径
*/
@override
public void savevisitinfo(string visitip, string path) {
string globalkey = sitemapconstants.site_visit_key;
string day = sitemapconstants.day(localdate.now());
string todaykey = globalkey + "_" + day;
// 用户的全局访问计数+1
long globaluservisitcnt = redisclient.hincr(globalkey + "_" + visitip, "pv", 1);
// 用户的当日访问计数+1
long todayuservisitcnt = redisclient.hincr(todaykey, "pv_" + visitip, 1);
redisclient.pipelineaction pipelineaction = redisclient.pipelineaction();
if (globaluservisitcnt == 1) {
// 站点新用户
// 今日的uv + 1
pipelineaction.add(todaykey, "uv"
, (connection, key, field) -> {
connection.hincrby(key, field, 1);
});
pipelineaction.add(todaykey, "uv_" + path
, (connection, key, field) -> connection.hincrby(key, field, 1));
// 全局站点的uv
pipelineaction.add(globalkey, "uv", (connection, key, field) -> connection.hincrby(key, field, 1));
pipelineaction.add(globalkey, "uv_" + path, (connection, key, field) -> connection.hincrby(key, field, 1));
} else if (todayuservisitcnt == 1) {
// 判断是今天的首次访问,更新今天的uv+1
pipelineaction.add(todaykey, "uv", (connection, key, field) -> connection.hincrby(key, field, 1));
if (redisclient.hincr(todaykey, "pv_" + path + "_" + visitip, 1) == 1) {
// 判断是否为今天首次访问这个资源,若是,则uv+1
pipelineaction.add(todaykey, "uv_" + path, (connection, key, field) -> connection.hincrby(key, field, 1));
}
// 判断是否是用户的首次访问这个path,若是,则全局的path uv计数需要+1
if (redisclient.hincr(globalkey + "_" + visitip, "pv_" + path, 1) == 1) {
pipelineaction.add(globalkey, "uv_" + path, (connection, key, field) -> connection.hincrby(key, field, 1));
}
}
// 更新pv 以及 用户的path访问信息
// 今天的相关信息 pv
pipelineaction.add(todaykey, "pv", (connection, key, field) -> connection.hincrby(key, field, 1));
pipelineaction.add(todaykey, "pv_" + path, (connection, key, field) -> connection.hincrby(key, field, 1));
if (todayuservisitcnt > 1) {
// 非当天首次访问,则pv+1; 因为首次访问时,在前面更新uv时,已经计数+1了
pipelineaction.add(todaykey, "pv_" + path + "_" + visitip, (connection, key, field) -> connection.hincrby(key, field, 1));
}
// 全局的 pv
pipelineaction.add(globalkey, "pv", (connection, key, field) -> connection.hincrby(key, field, 1));
pipelineaction.add(globalkey, "pv" + "_" + path, (connection, key, field) -> connection.hincrby(key, field, 1));
// 保存访问信息
pipelineaction.execute();
if (log.isdebugenabled()) {
log.info("用户访问信息更新完成! 当前用户总访问: {},今日访问: {}", globaluservisitcnt, todayuservisitcnt);
}
}
2.2 redis 管道封装
redis 管道技术允许在服务端未响应时,客户端继续向服务端发送请求,并最终一次性读取所有服务端的响应,从而实现批量操作。通过对 redis pipeline 使用姿势的封装,简化了调用过程,例如 com.github.paicoding.forum.core.cache.redisclient.pipelineaction 中的相关代码:
/**
* redis 管道执行的封装链路
*/
public static class pipelineaction {
private list<runnable> run = new arraylist<>();
private redisconnection connection;
public pipelineaction add(string key, biconsumer<redisconnection, byte[]> conn) {
run.add(() -> conn.accept(connection, redisclient.keybytes(key)));
return this;
}
public pipelineaction add(string key, string field, threeconsumer<redisconnection, byte[], byte[]> conn) {
run.add(() -> conn.accept(connection, redisclient.keybytes(key), valbytes(field)));
return this;
}
public void execute() {
template.executepipelined((rediscallback<object>) connection -> {
pipelineaction.this.connection = connection;
run.foreach(runnable::run);
return null;
});
}
}
@functionalinterface
public interface threeconsumer<t, u, p> {
void accept(t t, u u, p p);
}
2.3 计数更新与使用
pv/uv 的更新可以在 filter 中统一调用,为避免计数影响实际业务操作,采用异步更新策略:com.github.paicoding.forum.web.hook.filter.reqrecordfilter#initreqinfo。
private httpservletrequest initreqinfo(httpservletrequest request, httpservletresponse response) {
if (isstaticuri(request)) {
// 静态资源直接放行
return request;
}
stopwatch stopwatch = new stopwatch("请求参数构建");
try {
stopwatch.start("traceid");
// 添加全链路的traceid
mdcutil.addtraceid();
stopwatch.stop();
stopwatch.start("请求基本信息");
// 手动写入一个session,借助 onlineusercountlistener 实现在线人数实时统计
request.getsession().setattribute("latestvisit", system.currenttimemillis());
reqinfocontext.reqinfo reqinfo = new reqinfocontext.reqinfo();
reqinfo.sethost(request.getheader("host"));
reqinfo.setpath(request.getpathinfo());
if (reqinfo.getpath() == null) {
string url = request.getrequesturi();
int index = url.indexof("?");
if (index > 0) {
url = url.substring(0, index);
}
reqinfo.setpath(url);
}
reqinfo.setreferer(request.getheader("referer"));
reqinfo.setclientip(iputil.getclientip(request));
reqinfo.setuseragent(request.getheader("user-agent"));
reqinfo.setdeviceid(getorinitdeviceid(request, response));
request = this.wrapperrequest(request, reqinfo);
stopwatch.stop();
stopwatch.start("登录用户信息");
// 初始化登录信息
globalinitservice.initloginuser(reqinfo);
stopwatch.stop();
reqinfocontext.addreqinfo(reqinfo);
stopwatch.start("pv/uv站点统计");
// 更新uv/pv计数
asyncutil.execute(() -> springutil.getbean(sitemapserviceimpl.class).savevisitinfo(reqinfo.getclientip(), reqinfo.getpath()));
stopwatch.stop();
stopwatch.start("回写traceid");
// 返回头中记录traceid
response.setheader(global_trace_id_header, optional.ofnullable(mdcutil.gettraceid()).orelse(""));
stopwatch.stop();
} catch (exception e) {
log.error("init reqinfo error!", e);
} finally {
if (!envutil.ispro()) {
log.info("{} -> 请求构建耗时: \n{}", request.getrequesturi(), stopwatch.prettyprint(timeunit.milliseconds));
}
}
return request;
}
目前站点的统计信息在前台只显示全局站点的统计情况,使用时直接从 hash 中获取对应的计数即可:com.github.paicoding.forum.service.sitemap.service.impl.sitemapserviceimpl#querysitevisitinfo。
/**
* 查询站点某一天or总的访问信息
*
* @param date 日期,为空时,表示查询所有的站点信息
* @param path 访问路径,为空时表示查站点信息
* @return
*/
@override
public sitecntvo querysitevisitinfo(localdate date, string path) {
string globalkey = sitemapconstants.site_visit_key;
string day = null, todaykey = globalkey;
if (date != null) {
day = sitemapconstants.day(date);
todaykey = globalkey + "_" + day;
}
string pvfield = "pv", uvfield = "uv";
if (path != null) {
// 表示查询对应路径的访问信息
pvfield += "_" + path;
uvfield += "_" + path;
}
map<string, integer> map = redisclient.hmget(todaykey, arrays.aslist(pvfield, uvfield), integer.class);
sitecntvo siteinfo = new sitecntvo();
siteinfo.setday(day);
siteinfo.setpv(map.getordefault(pvfield, 0));
siteinfo.setuv(map.getordefault(uvfield, 0));
return siteinfo;
}
前台使用路径:

3 小结
基于 redis 实现 pv/uv 统计主要依靠两个关键知识点:
- hash: incr:利用 redis 的 hash 结构结合 incr 命令实现原子计数。
- pipeline:通过管道方式实现批量操作,提高操作效率。
最后提出一个思考问题:当站点访问量剧增,一天达到几百万的访问量时,通过记录 ip 来实现 uv 计数会导致用户访问记录存储开销巨大,此时可以考虑使用 redis 中的 hyperloglog 来解决这一问题,它利用数学上的概率统计分布原理,能在空间复杂度较低的情况下实现近似的计数统计。
到此这篇关于基于redis 实现网站pv/uv数据统计的文章就介绍到这了,更多相关redis pv/uv数据统计内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论