1.进程地址空间分布
进程地址空间分布图
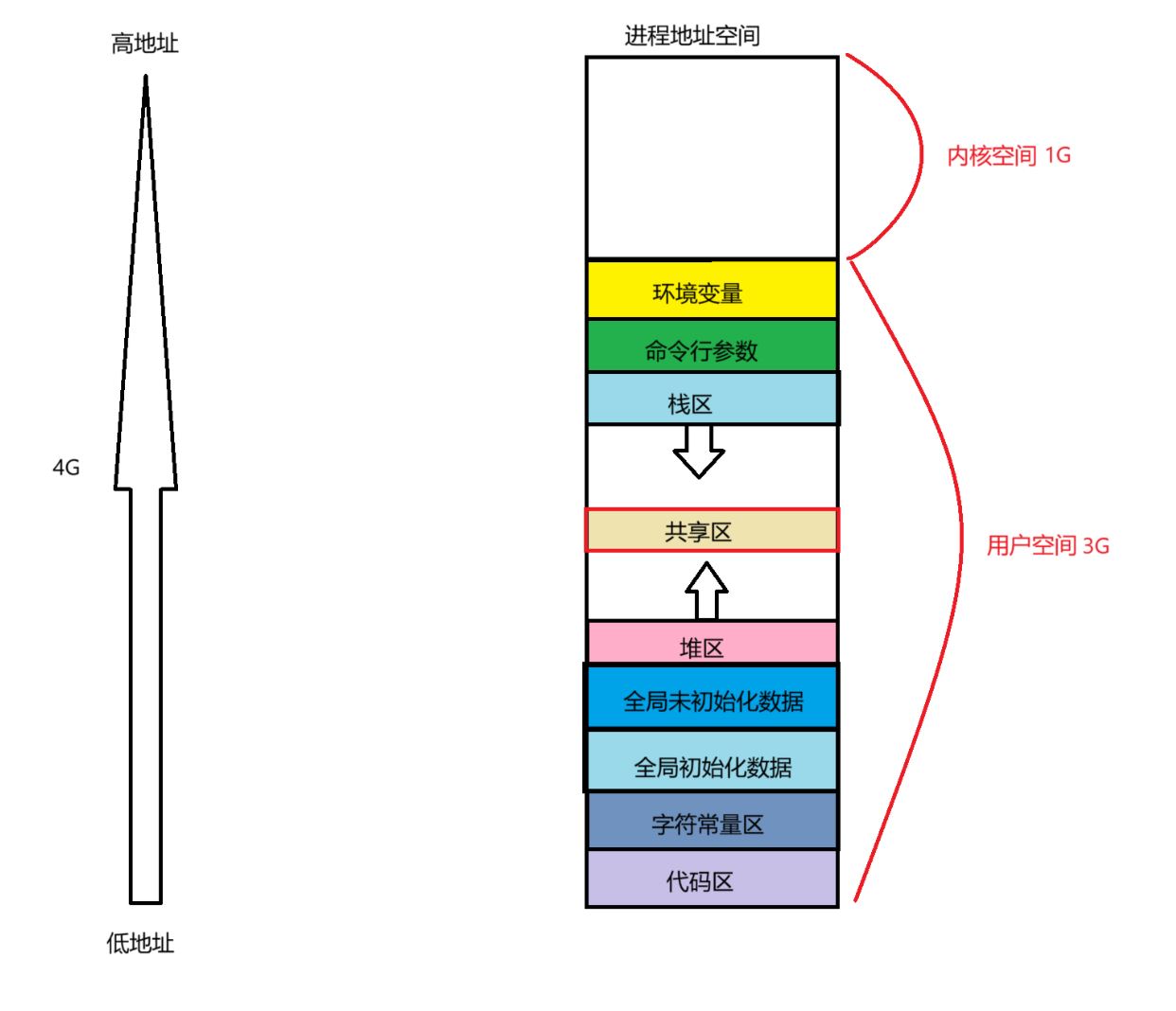
栈区是向地址减小方向开空间(栈是先使用高地址),而堆区是向地址增长方向申请空间(堆是先使用低地址),堆栈之间的共享区,主要用来加载动态库。
我们通过如下代码来验证一下是否符合上面的地址空间分布:
#include<stdio.h>
#include<stdlib.h>
int g_unval;//未初始化
int g_val = 100;//初始化
int main(int argc, char* argv[], char* env[])
{
const char* p = "hello bit";//p是指针变量(栈区),p指向字符常量h(字符常量区)
char* q = (char*)malloc(10);//q 存放堆区地址,&q 指的是栈区地址
printf("env addr: %p\n", env[0]);//环境变量
printf("args addr %p\n", argv[0]);//命令行参数
printf("stack addr: %p\n", &p);//p先定义,先入栈
printf("stack addr: %p\n", &q);//栈区
printf("heap addr: %p\n", q); //堆区
printf("global val: %p\n", &g_val); //全局初始化
printf("global uninit val: %p\n", &g_unval); //全局未初始化
printf("read only : %p\n", p); //字符常量区
printf("code addr: %p\n", main);//代码区起始地址
return 0;
}运行结果如下:
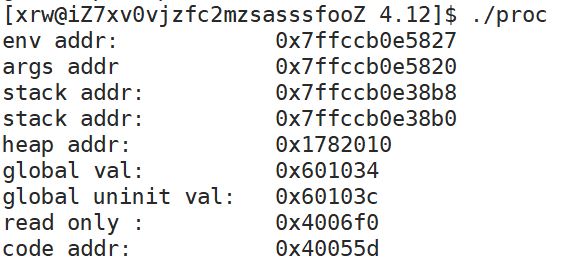
地址自上而下,可以看到它的地址分布严格遵守上面的进程地址分布图
进程地址空间,会在进程的整个生命周期内一直存在,直到进程退出,所以全局变量会一直存在。
2. 地址空间是虚拟的
进程地址空间不是实际的物理内存而是一个虚拟的地址内存
我们如何验证这个观点呢??通过如下代码:
#include<stdio.h>
#include<unistd.h>
int g_val = 10;
int main()
{
printf("刚开始时的g_val:%d\n", g_val);
pid_t id = fork();
if (id == 0)
{
//子进程
g_val = 100;
printf("子进程中的g_val:%d\n", g_val);
printf("子进程中g_val的地址:%p\n", &g_val);
}
else if (id > 0)
{
//父进程
printf("父进程中的g_val:%d\n", g_val);
printf("父进程中g_val的地址:%p\n", &g_val);
}
return 0;
}运行结果如下:
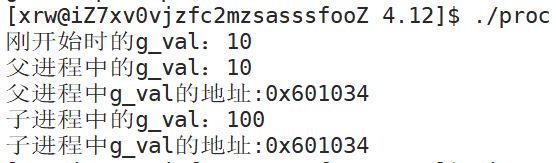
可以看到这里父子进程中g_val的地址是相同的,而g_val的值却是不同的。
根据常识我们都知道,一个地址不可能存放有两个不同的数据,因此我们可以得出进程地址空间中的地址并不是真实的物理内存地址,而是一个虚拟地址!!
虚拟地址是由操作系统提供的,由冯诺依曼体系结构我们知道任何数据在启动时必须加载到物理内存,所以肯定需要将虚拟地址转化成物理地址。因此操作系统需要将虚拟地址转化成物理地址。
进程地址空间是由操作系统虚拟出来的内存, 那么操作系统是如何划分进程地址空间区域的??
进程地址空间本质上是一种数据结构,是多个区域的集合。在linux内核中,有这样一个结构体:struct mm_struct,在这个结构体里面进行区域的划分(栈区堆区等区域)。
struct mm_struct
{
//...
unsigned long heap_start;//堆区
unsigned long heap_end;
unsigned long stack_start;//栈区
unsigned long stack_end;
unsigned long uninit_start;//未初始化区
unsigned long uninit_end;
unsigned long init_start;//初始化区
unsigned long init_end;
unsigned long code_start;//代码区
unsigned long code_end;
//...
}这里还存在一个疑问??假设物理内存是4g的情况下,那么每一个进程中都有一个4g的进程地址空间,我们都知道一个内存可以加载多个进程,那么物理内存足够给每一个进程中的进程地址空间的地址数据进行映射存放下来吗?
答案是够的,每一个进程都认为他们会使用4g的物理内存,但实际上他们所使用的空间远远小于4g的内存,因此内存中才能加载多个进程。
3.虚拟地址和物理地址的映射
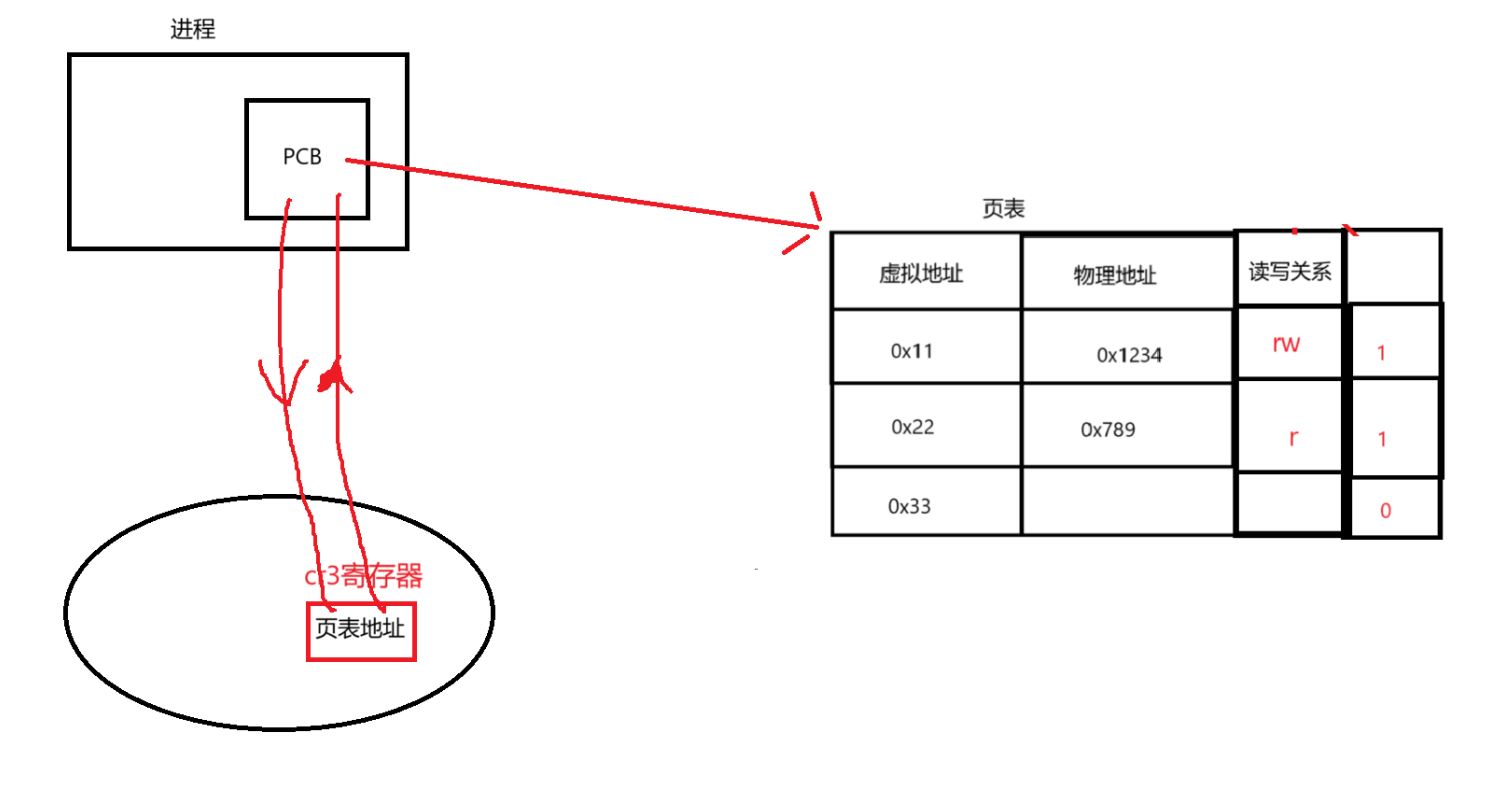
每一个进程都会有一个pcb(task_struct结构体),而pcb中有一个指针指向各自进程的地址空间,进程将自己的代码和数据首先放在虚拟地址空间的对应的区域,在这其中会有一种表结构,叫做页表,页表的核心工作就是完成虚拟地址到物理地址之间的映射。之后,我们的代码和数据通过页表的映射加载到实际的物理内存中。
因此通过页表建立的虚拟与物理地址之间的对应关系成功将进程中的代码和数据存入到了内存中
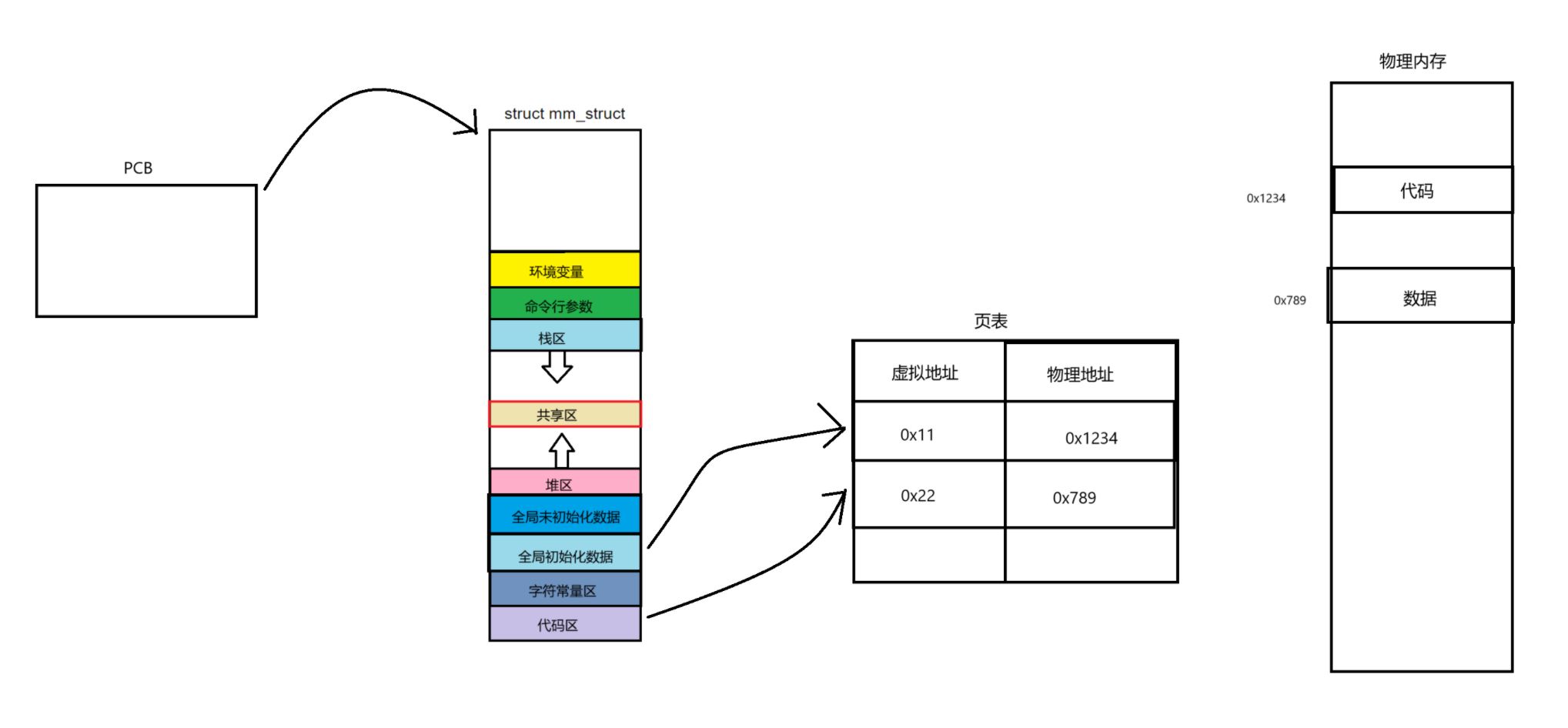
这里我们回答几个问题。
1.不同进程的虚拟地址可以一样吗??
可以的,因为不同进程之间的虚拟地址可以是一样的,每一个进程都有独属于自己的页表,他们通过页表映射到不同的物理地址。
2.不同进程的虚拟地址在页表映射的物理地址是否会重复??
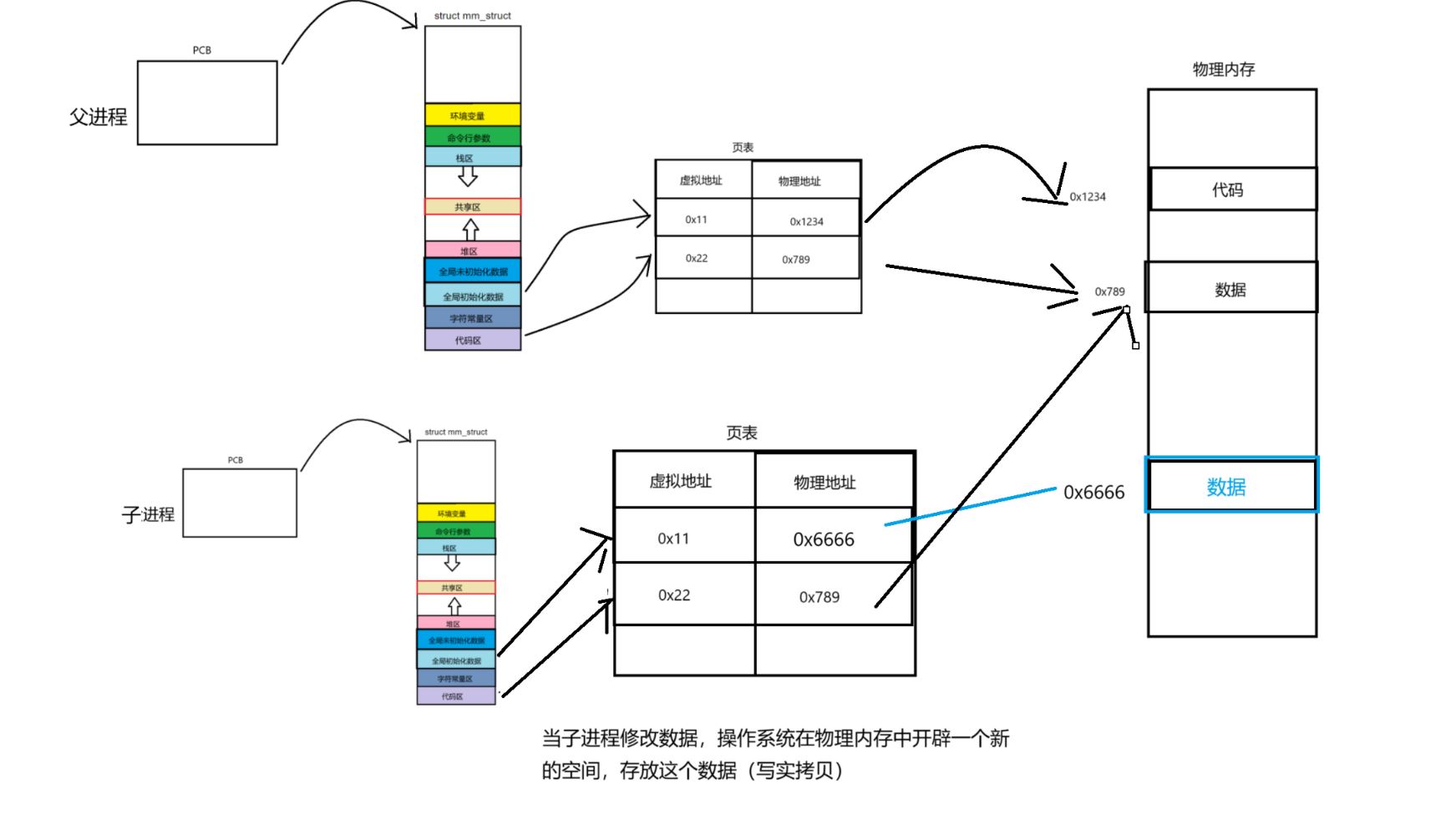
答案是不会的。但是存在着一种特殊情况,当父进程创造子进程,子进程会以父进程的地址空间和页表的映射等为模板,创造属于自己的进程地址和页表,当子进程不对代码和数据做改变时,子进程的页表还是会指向和父进程一样的物理地址。
但是当子进程对数据修改时,操作系统会在物理内存中进行写实拷贝,开辟出一个新的物理地址,里面存放子进程修改后的数据,并且此时页表会更新映射的物理地址。(这就回答了上面父子进程中为什么g_val的值不同,而进程地址相同的原因)
4.地址空间和页表存在的意义
1.保护物理内存,维持进程的独立性
如果进程直接访问物理内存,若进程中存在代码问题(如指针越界等等),那么这个进程很可能会访问到别的进程的数据并对该数据进行修改,这就破坏了进程的独立性。而有了虚拟地址之后,通过页表只能访问自己映射到的物理内存保证了进程的独立性。
2.页表可以进行越界行为的检查
- 第一种检查,通常为指针越界的检查 :
当发生越界行为,系统会检查越界后的地址地址是否在对应的区域(比如指针原本是栈区,越界后依然在栈区),编译器会通过mm_struct结构体里面该区域的范围比对,如果还在对应的区域那么编译器会认为合法,如果不在则非法。
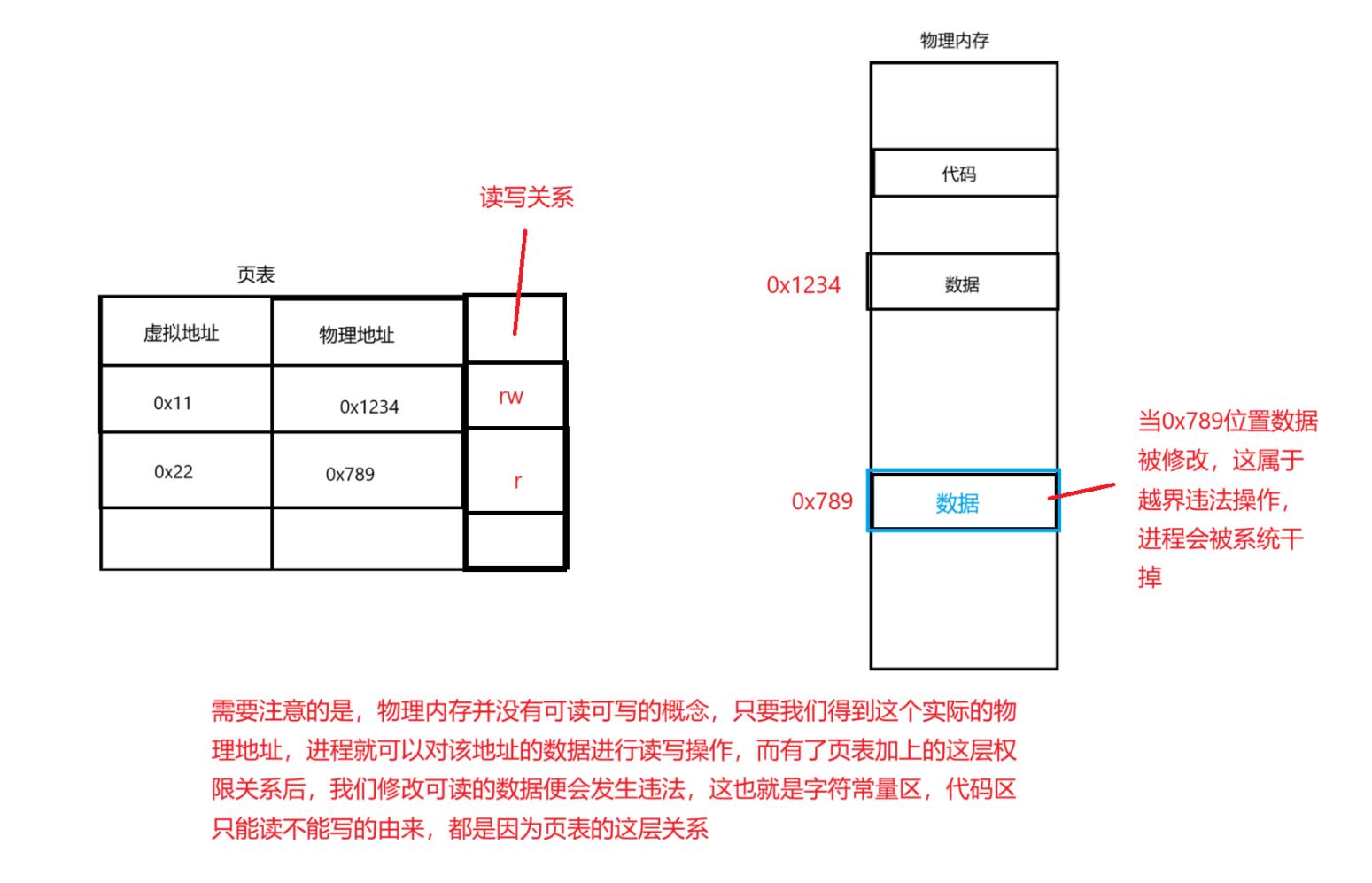
- 第二种检查,检查是否对常量区的数据进行修改:
其实页表也有一种权限管理判断是否可以读写,当你对数据区进行映射时,数据区是可以读写的,相应的在页表中的映射关系中的权限就是可读可写,但是当你对代码区和字符常量区进行映射时,因为这两个区域是只读的,相应的在页表中的映射关系中的权限就是只读,如果你对这段区域进行了写,通过页表当中的权限管理,操作系统就直接就将这个进程干掉。
3.降低内存和进程管理的耦合
- 若没有进程地址空间,当进程退出时,内存管理需要尽快对该进程回收释放,而有进程加载到内存时,内存管理又要及时分配资源,耦合度太高。
- 当有了进程地址空间后,一个进程需要资源的时候,通过页表映射去要就即可。
- 内存管理就只需要知道哪些内存区域(配置)是无效的,哪些是有效的(被页表映射的就是有效的,没有被页表映射的就是无效的)。
- 当进程退出,页表也随之退出,没有了映射关系后,物理内存将该进程的数据映射的物理地址设置为无效即可。同理有进程进入时设置为有效。
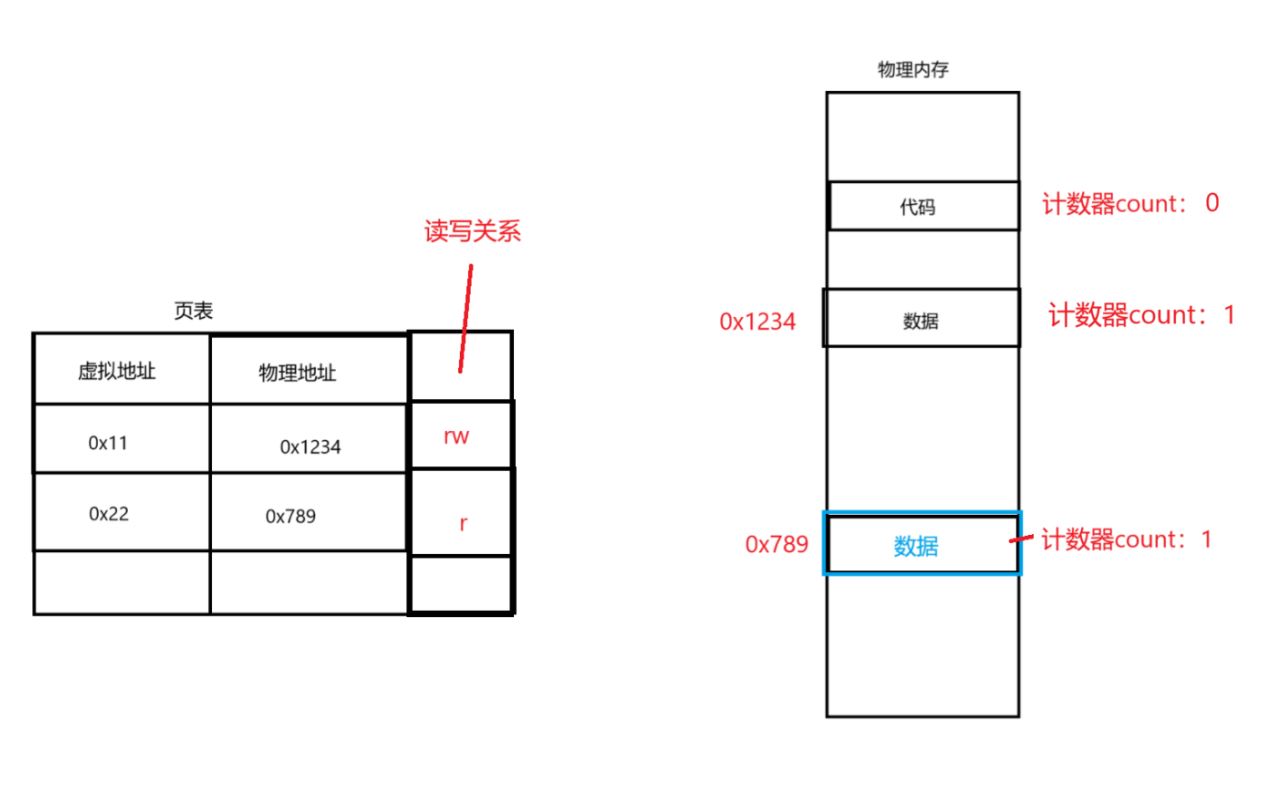
物理内存如何知道某个地址是否被映射(有效)??
可以理解为在每个物理内存的地址出有一个计数器,当计数器为1,即该处被映射,为0时则没被映射。
4.内存管理如何将一些大型数据加载到物理内存
内存管理是通过延迟加载的方式加载到物理内存的。一个大型进程,内存管理首先会给你加载小一部分先供你使用,当你使用完时,会先将进程置为睡眠状态,然后将进程再唤醒,再加载一部分数据代码,进程再继续使用,依次反复。对于用户来说,唯一感觉到的是我的游戏运行的慢了。
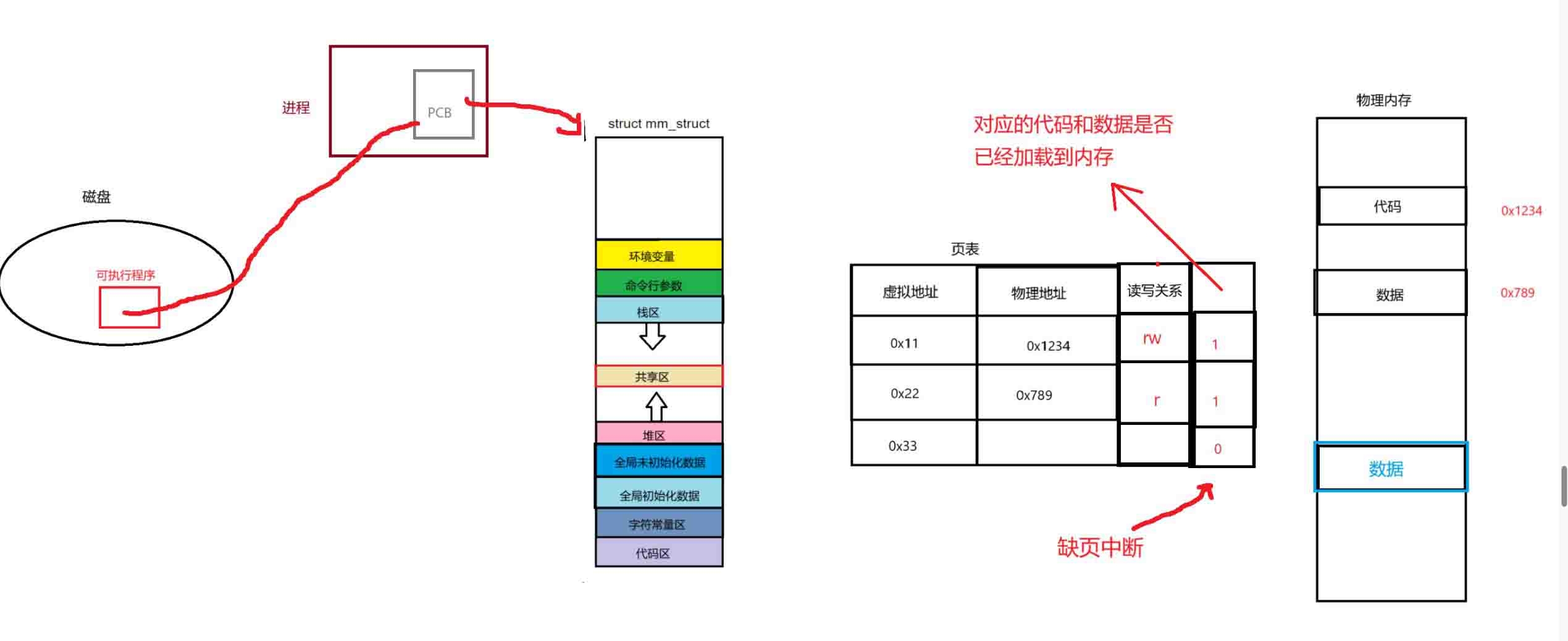
页表中还有一个管理权限判断判断进程的代码和数据是否已经加载到了内存,0为没有加载到内存,而1则相反,这只是一个简化理解
磁盘会将这个大型可执行程序的数据和代码一点点的放入到内存当中,而操作系统对物理内存的分配是:进程用到哪里就加载多少数据代码原则。
进程所有的代码和数据都有对应的虚拟地址,因此对于那些还不需要用到的数据代码,页表会在对应权限标0表示没有加载到内存,当需要这个数据代码的时候,操作系统会在物理内存里开辟空间,并且访问磁盘里对应的代码和数据。
这些理解都是一些比较浅的理解,对于页表的具体理解,需要后面进行更深的理解。
最后还有两个问题,cpu如何访问进程的页表??cpu对页表做出修改后,进程如何保持更新呢??
页表的地址属于进程的上下文。
cpu中有一个叫做cr3的寄存器存放着页表的地址(可以把页表想象成unordered_map结构的对象),cpu也是通过该地址访问页表的,当进程运行完后,进程会带走自己的临时数据,也就是进程的上下文,所以进程也会带走页表的地址,这样就做到了保持更新。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论